library(tidyverse)
theme_set(theme_minimal())
library(magick)
library(hfapi)
library(paws)
source("data/rekognition.R")3 Automatische Bildanalyse
Zu Beginn laden wir zunächst das tidyverse Paket und setzen ein schöneres Theme für alle Grafiken, die wir erstellen. Außerdem laden wir das magick Paket, mit dem sich Bilder laden und bearbeiten lassen. Für Aufrufe der Hugging Face API laden wir unser hfapi Paket. Für weitere Funktionen benötigen wir Zugriff auf die Amazon Rekognition API, die in der Datei data/rekognition.Reingerichtet ist, das wiederum das paws Paket benötigt. Rekognition ist ein kommerzieller Dienst, d.h. es entstehen (sehr geringe) Kosten pro Bild. Hierfür benötigt man einen API-Key, siehe die Datei.
3.1 Gesichtserkennung
Ein klassischer Anwendungsfall für die automatische Bildcodierung ist die Gesichtserkennung. Hierzu öffnen wir zunächst ein Stock Photo von https://pixabay.com.
magick::image_read("https://cdn.pixabay.com/photo/2017/06/20/22/14/man-2425121_1280.jpg")
Dieses Bild senden wir nun mit der Funktion get_faces() an die Rekognition API. Diese liefert einen Datenframe mit zwei Zeilen zurück - einen pro erkanntem Gesicht. Als Spalten erhalten wir neben den Positionsangaben, um das Gesicht im Bild identifizieren zu können, das automatisch codierte Geschlecht, das sichtbare Alter (mit Minimum und Maximum) sowie automatisch codierte Emotionen wie happy oder sad.
get_faces("https://cdn.pixabay.com/photo/2017/06/20/22/14/man-2425121_1280.jpg")# A tibble: 2 × 18
person gender age low high smile angry calm confused disgusted fear
<chr> <chr> <dbl> <dbl> <dbl> <lgl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 Female 36 32 40 TRUE 0 0 0 0 0
2 2 Male 25 21 29 TRUE 0 0 0 0 0
# ℹ 7 more variables: happy <dbl>, sad <dbl>, surprised <dbl>, width <dbl>,
# height <dbl>, left <dbl>, top <dbl>
Soziodemographie von IfP-Absolvent:innen
Als kleines Beispiel für eine bildbasierte Analyse untersuchen wir die Zusammensetzung von IfP-Absolvent:innen. Auf der IfP-Webseite findet sich ein schönes großes Bild von der Absolvent:innenverabschiedung 2019.
magick::image_read("https://www.ifp.uni-mainz.de/files/2019/10/MG_4278-e1571393840928.jpg")
Dieses Bild senden wir zur automatischen Verarbeitung an Amazon Recognition und speichern das Ergebnis als eigenes Objekt zur Weiterverwendung ab.
ifp_grad_faces <- get_faces("https://www.ifp.uni-mainz.de/files/2019/10/MG_4278-e1571393840928.jpg")
ifp_grad_faces# A tibble: 100 × 18
person gender age low high smile angry calm confused disgusted
<chr> <chr> <dbl> <dbl> <dbl> <lgl> <dbl> <dbl> <dbl> <dbl>
1 1 Male 31 27 35 TRUE 0.00300 0.0000179 0.000352 0
2 2 Male 29 25 33 TRUE 0.0000119 0 0.00230 0.0922
3 3 Male 35 31 39 TRUE 0.336 0.233 1.04 0.00620
4 4 Female 31 27 35 TRUE 0 0 0 0
5 5 Female 48 44 52 TRUE 0.0000834 0.000817 0.000119 0.0000417
# ℹ 95 more rows
# ℹ 8 more variables: fear <dbl>, happy <dbl>, sad <dbl>, surprised <dbl>,
# width <dbl>, height <dbl>, left <dbl>, top <dbl>Wie wir sehen, wurden 100 Gesichter auf dem Bild erkannt - auch sehr kleine im Hintergrund. Nun fassen wir die codierten Daten nach (automatisch erkanntem) Geschlecht zusammen. Wir fügen mit add_count() die Häufigkeiten von männlichen und weiblichen Gesichtern hinzu, und berechnen anschließend geschlechtsspezifische Mittelwerte ifür die Variablen age und einige Emotionen.
ifp_grad_faces |>
add_count(gender) |>
group_by(gender, n) |>
summarise_at(vars(age, happy, sad, surprised), lst(mean))# A tibble: 2 × 6
# Groups: gender [2]
gender n age_mean happy_mean sad_mean surprised_mean
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 Female 88 38.2 83.4 2.38 2.42
2 Male 12 32 63.8 0.0624 13.5 Wir sehen in den Ergebnissen einen - wenig überraschend - hohen Frauenanteil von 88%. Das vom Modell geschätzte Alter ist allerdings sehr hoch für BA- und MA-Absolvent:innen, hier scheint die automatische Klassifikation weniger valide als erhofft. Außerdem sehen wir, dass die Frauen deutlich häufiger als happy klassifiziert wurden, währen die männlichen Absolventen häufiger überrascht scheinen. Inwieweit das ein Artefakt der automatischen Codierung ist, bleibt zu diskutieren.
3.2 Bildbeschreibung
In den folgenden Übungen werden Bilder automatisch beschrieben, sei es als Freitext oder hinsichtlich (vorgegebener) Kategorien.
3.2.1 Automatische Captions
Wir beginnen mit einem weiteren Stock Photo, diesmal von einer Demonstration.
magick::image_read("https://cdn.pixabay.com/photo/2020/02/29/22/41/demonstration-4891291_1280.jpg")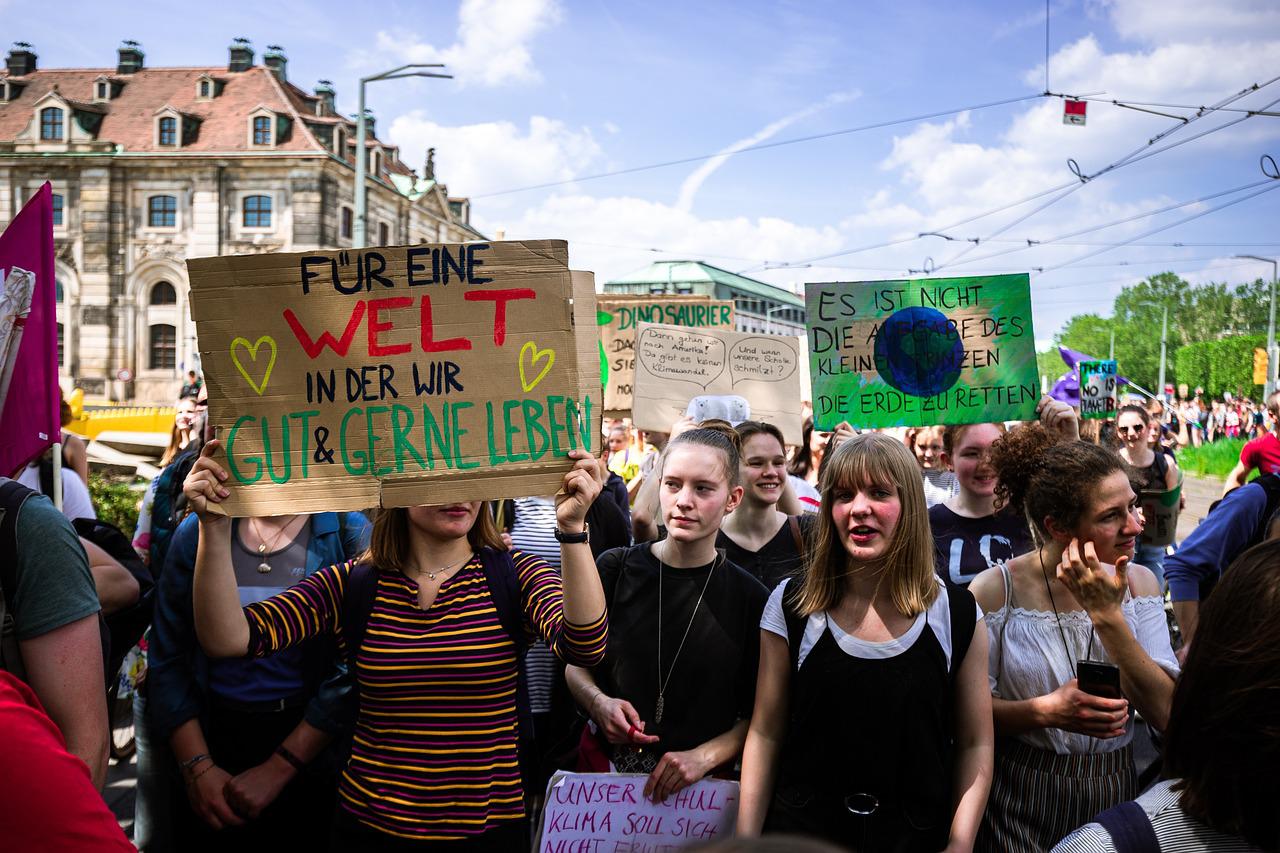
Welche Bildbeschreibung liefert ein aktuelles State-of-the-Art-Sprachmodell (BLIP), dass mit hunderttausenden Bildern und dazugehörigen Captions trainiert wurde. Wir rufen die entsprechende API auf Hugging Face auf und erhalten als Antwort einen kurzen Text.
hfapi::image_to_text("https://cdn.pixabay.com/photo/2020/02/29/22/41/demonstration-4891291_1280.jpg")[1] "Waiting 75 seconds for model to load."# A tibble: 1 × 1
generated_text
<chr>
1 people holding signs and protesting in a protest in a city3.2.2 Generische Labels
Neben einem Beschreibungstext können Bilder auch automatisch gelabelt werden, d.h. eine Reihe von Kategorien werden dem Bild zugeordnet oder nicht. Als Basis für zahlreiche Bildklassifikationsmodelle dient der ImageNet-Datensatz, in dem Bilder bzw. Bildausschnitte einem von 1000 Labels zugeordnet wurden. Diese Labels reichen von Gegenständen über Tierarten bis hin zu Personen. Hier rufen wir ein auf Hugging Face vorhandenes Basismodell mit der Funktion image_classification() auf.
image_classification("https://cdn.pixabay.com/photo/2020/02/29/22/41/demonstration-4891291_1280.jpg")# A tibble: 5 × 2
score label
<dbl> <chr>
1 0.0872 carton
2 0.0370 crate
3 0.0242 plastic bag
4 0.0236 stage
5 0.0232 mortarboardDie Labels sind für unsere Zwecke eher wenig geeignet, zumal das Modell auch nicht sehr hohe Zuversichtsscores für deren Auftreten vergibt. Kann Amazon Rekognition es besser? Mit der Funktion get_labels() senden wir das Bild an die Rekognition API, die wiederum einen Datenframe mit den Labels und den Confidence Scores zurückgibt. Diese Scores fallen schon einmal deutlich höher aus, und auch die Labels selbst scheinen nützlicher zu sein.
get_labels("https://cdn.pixabay.com/photo/2020/02/29/22/41/demonstration-4891291_1280.jpg")# A tibble: 31 × 2
label conf
<chr> <dbl>
1 People 99.2
2 Person 99.2
3 Parade 99.1
4 Protest 99.1
5 Adult 99.1
# ℹ 26 more rowsDa uns hier nur die ersten Zeilen ausgegeben werden, ziehen wir die Werte der Spalte label nochmals gezielt heraus.
get_labels("https://cdn.pixabay.com/photo/2020/02/29/22/41/demonstration-4891291_1280.jpg") |>
pull(label) [1] "People" "Person" "Parade"
[4] "Protest" "Adult" "Female"
[7] "Woman" "Male" "Man"
[10] "Face" "Head" "Accessories"
[13] "Jewelry" "Necklace" "Text"
[16] "Flag" "Transportation" "Vehicle"
[19] "Electronics" "Mobile Phone" "Phone"
[22] "Crowd" "Adventure" "Leisure Activities"
[25] "Car" "City" "Banner"
[28] "Offroad" "Urban" "Photography"
[31] "Portrait" Leider wissen wir nicht, wie viele und welche Labels es insgesamt bei Rekognition gibt, so dass wir die Trefferquote nur schwer einschätzen können.
3.2.3 Spezifische Labels
Neben der generischen Vergabe von Labels können wir auch gezielt spezifische Bildinhalte codieren, etwa ob bestimmte Gegenstände oder Darstellungsweisen in einem Bild vorhanden sind. Ein typischer Anwendungsfall sind problematische Inhalte, die z.B. im Rahmen einer Content Moderation Policy herausgefiltert werden: Nackheit, Gewalt, Drogen- oder Alkoholkonsum, etc. Hierfür laden wir ein weiteres Beispielbild, ein altes Albumcover.
magick::image_read("https://flashbak.com/wp-content/uploads/2017/04/vintage-album-cover-alcohol-24.jpg")
Rekognition bietet eine eigene Moderation API an, mit der automatisch potenziell problematische Bildinhalte klassifiziert werden. Mit der Funktion get_mod_content() erhalten wir einen Datenframe mit den erkannten Inhalten, die ggf. moderiert bzw. zensiert werden sollten.
get_mod_content("https://flashbak.com/wp-content/uploads/2017/04/vintage-album-cover-alcohol-24.jpg")# A tibble: 4 × 3
label conf parent
<chr> <dbl> <chr>
1 Revealing Clothes 74.2 "Suggestive"
2 Suggestive 74.2 ""
3 Alcoholic Beverages 47.4 "Alcohol"
4 Alcohol 47.4 "" Das Modell hat sowohl suggestive Kleidung als auch sichtbaren Alkoholkonsum erkannt, die Tablette unbekannter Provenienz allerdings nicht.
Als zweites Beispiel wählen wir wieder ein Modell, dass auf Hugging Face gehostet wird: ein Bildklassifikator, mit dem Essen codiert werden kann.
magick::image_read("https://cdn.pixabay.com/photo/2017/03/27/13/54/bread-2178874_960_720.jpg")
Wir übergeben der Funktion image_classification() aus unserem hfapi Paket eine eigene URL, nämlich die das vortrainierten Modells, und erhalten die entsprechenden Codierungen zurück.
hfapi::image_classification("https://cdn.pixabay.com/photo/2017/03/27/13/54/bread-2178874_960_720.jpg", url = "https://api-inference.huggingface.co/models/Kaludi/food-category-classification-v2.0")[1] "Waiting 20 seconds for model to load."# A tibble: 5 × 2
score label
<dbl> <chr>
1 0.637 Bread
2 0.279 Meat
3 0.0432 Dairy
4 0.0153 Rice
5 0.00934 Vegetable