library(tidyverse)
theme_set(theme_minimal())2 Automatische Textanalyse
In diesem Kapitel arbeiten wir mit einem Datensatz der Tweets von Donald Trump aus dem Jahr 2016 enthält. Die Daten wurden von David Robinson gesammelt und bereitgestellt. Das besondere an diesem Datensatz ist, dass es eine Angabe zur App gibt, mit denen die Tweets erstellt wurden, und hier zwei unterschiedliche Handy-Apps (Android und iPhone) häufig genutzt wurden. Die Frage ist: Hatte Donald Trump zwei Telefone oder wurde sein Twitter-Auftritt von mehreren Personen bespielt?
Zu Beginn laden wir zunächst das tidyverse Paket und setzen ein schöneres Theme für alle Grafiken, die wir erstellen. Die später benötigten Pakete werden weiter unten geladen, RStudio sollte uns anbieten, diese ggf. nachzuinstallieren.
Für die Textanalyse benötigen wir zwei neue Pakete. Einerseits hfapi für den Zugriff auf die API auf der Plattform Hugging Face, zum anderen quanteda, das viele Standardfunktionen für die Textanalyse bereitstellt.
# remotes::install_github("ccsmainz/hfapi", dependencies = FALSE, force = TRUE)
library(hfapi)
library(quanteda)Dann laden wir die Daten und wählen anschließend die benötigten Variablen (Spalten) mit select() aus. Zudem erstellen wir eine neue Variable source, die Informationen enthält, welches Betriebssystem auf dem Handy genutzt wurde.
# Datensatz laden
load(url("http://varianceexplained.org/files/trump_tweets_df.rda"))
tweets <- trump_tweets_df |>
select(id, statusSource, text, created) |>
# Die verschiedenen Betriebssysteme extrahieren
extract(statusSource, "source", "Twitter for (.*?)<") |>
filter(source %in% c("iPhone", "Android")) |>
mutate(text = stringi::stri_enc_toutf8(text, validate = T))
tweets# A tibble: 1,390 × 4
id source text created
<chr> <chr> <chr> <dttm>
1 762669882571980801 Android "My economic policy speech wil… 2016-08-08 15:20:44
2 762641595439190016 iPhone "Join me in Fayetteville, Nort… 2016-08-08 13:28:20
3 762439658911338496 iPhone "#ICYMI: \"Will Media Apologiz… 2016-08-08 00:05:54
4 762425371874557952 Android "Michael Morell, the lightweig… 2016-08-07 23:09:08
5 762400869858115588 Android "The media is going crazy. The… 2016-08-07 21:31:46
# ℹ 1,385 more rows2.1 Worthäufigkeiten und reguläre Ausdrücke
Eines der einfachsten und meistgenutzten Verfahren der automatischen Textanalyse ist das Zählen von bestimmten Features (Wörter, Sonderzeichen, Emojis, etc.). In R ist diese Aufgabe sehr einfach mit dem Befehlt str_count() aus dem tidyverse Paket zu lösen. Wir erstellen eine neue Variable, die einfach zählt, wie oft der Suchbegriff Hillary in den Tweets vorkommt.
tweets |>
mutate(hillary = str_count(text, "Hillary")) |>
select(text, hillary) |>
tail()# A tibble: 6 × 2
text hillary
<chr> <int>
1 "\"@deedeegop: Thank u Mr. Trump, I look forward to when u are electe… 0
2 "\"@constant4change: Trump tops Dem candidates on Google before Dem d… 0
3 "\"@autumnandews08: @realDonaldTrump @jonkarl Hillary is so worried b… 1
4 "\"@DomineekSmith: @realDonaldTrump is the best Republican presidenti… 0
5 "Another great accolade for @TrumpGolf. Highly respected Golf Odyssey… 0
# ℹ 1 more rowDas Suchmuster muss nicht nur ein einzelner Begriff sein, sondern kann auch komplexe Regeln enthalten, sogenannte reguläre Ausdrücke (eng. Regular Expressions). Diese beinhalten eine Vielzahl an Platzhaltern und anderen Möglichkeiten, um etwa URLs oder Hashtags zu finden. Außerdem können mit regulären Ausdrücken auch Treffer extrahiert werden, die man dann weiterverarbeiten kann. Die Funktion dafür ist str_extract(). Als regulären Ausdruck verwenden wir #\\w+ dieser sucht nach einem Hashtag (#), gefolgt von einem oder mehreren Buchstaben, Ziffern oder Unterstrichen. Anschließend zählen wir die neue hashtag-Variable aus.
tweets |>
mutate(hashtag = str_extract(text, "#\\w+")) |>
select(text, hashtag) |>
count(hashtag, sort = TRUE) |>
na.omit()# A tibble: 103 × 2
hashtag n
<chr> <int>
1 #Trump2016 107
2 #MakeAmericaGreatAgain 81
3 #CrookedHillary 17
4 #AmericaFirst 16
5 #VoteTrump 15
# ℹ 98 more rows2.2 Named Entity Recognition
Eine andere Art von Information ist die Named Entity Recognition (NER), eine Standardaufgabe in der Computerlinguistik. Hierbei werden Eigennamen von Personen, Organisationen oder Orten erkannt und extrahiert. Auch diese können wir dann einfach auszählen. Da NER je nach Sprache unterschiedlich komplexe Regeln erfordern würde, haben sich in der Praxis vortrainierte Deep-Learning-Modelle durchgesetzt. Ein solches rufen wir nachfolgend über die Web-API von Hugging Face auf. Da die API ein Rate Limit hat, d.h. nicht unbegrenzt viele Texte gleichzeitig verarbeitet werden, wählen wir nur die ersten 100 Tweets aus, senden diese an den Server und bekommen die Liste extrahierte Eigennamen zurück.
tweet_entities <- hfapi::text_ner(tweets$text[1:100])
tweet_entities |>
as_tibble()# A tibble: 252 × 6
text entity_group score word start end
<chr> <chr> <dbl> <chr> <int> <int>
1 "Join me in Fayetteville, North Carolina… LOC 0.979 Faye… 11 23
2 "Join me in Fayetteville, North Carolina… LOC 1.00 Nort… 25 39
3 "#ICYMI: \"Will Media Apologize to Trump… ORG 0.609 ##C 2 3
4 "#ICYMI: \"Will Media Apologize to Trump… ORG 0.758 Media 14 19
5 "#ICYMI: \"Will Media Apologize to Trump… PER 0.995 Trump 33 38
# ℹ 247 more rowsWie wir sehen, ist das auch das gut trainierte Sprachmodell nicht fehlerlos, allerdings scheinen die unvollständigen Entitäten nicht sehr relevant für unsere Fragestellung. Daher können wir den Datensatz auf Orte filtern (entity_group ist LOC) und dann die word Spalte auszählen.
tweet_entities |>
filter(entity_group == "LOC") |>
count(word, sort = TRUE) |>
as_tibble()# A tibble: 46 × 2
word n
<chr> <int>
1 Pennsylvania 6
2 Florida 5
3 Iran 4
4 Jacksonville 4
5 Virginia 4
# ℹ 41 more rowsWir sehen, dass am häufigsten von Pennsylvania und Florida die Rede ist.
2.3 Document-Feature-Matrix
Für die oben vorgestellten Analysen können wir die Texte direkt als Spalte verwenden, weil nur einzelne Informationen daraus extrahiert werden. Was aber ist mit Analysen, die sich auf den ganzen Tweet-Text beziehen? Hierfür ist es nötig, aus der Textspalte ein Format zu generieren, das man mit statistischen Verfahren auswerten kann, d.h. eine Matrix von Zahlen, in denen die Reihen die Analyseeinheit widergeben. Eine grundlegende numerische Darstellung von Texten erlaubt der Bag-of-Words Ansatz (BoW). Dabei wird lediglich gezählt, wie oft jeder Begriff im Text vorkommt. Grammatikalische Zusammenhänge werden nicht berücksichtigt. Diese Form der numerischen Repräsentation kann in einer Matrix dargestellt werden, der Document-Feature-Matrix (DFM). Jede Zeile repräsentiert ein Dokument (bspw. Tweet), jede Spalte ein Wort (oder allgemein Feature). Features können auch einzelne Zeichen, Wortgruppen, Satzzeichen o.ä. sein, aber am einfachsten sind Wörter für uns zu verstehen.
Mit der Hilfe von quanteda lässt sich schnell eine Document-Feature-Matrix (DFM) erstellen. Dazu nutzen wir die Funktionen tokens() und dfm(). Als Input müssen wir lediglich die Spalte (Variable) angeben, welche die Tweets enthält. Mit tokens() werden die einzelnen Features aus dem Text extrahiert, mit dfm() in einer entsprechenden Matrix mit Häufigkeiten zusammengefasst.
tweets$text |>
quanteda::tokens() |>
quanteda::dfm()Document-feature matrix of: 1,390 documents, 4,463 features (99.58% sparse) and 0 docvars.
features
docs my economic policy speech will be carried live at 12
text1 1 1 1 1 1 1 1 1 1 1
text2 0 0 0 0 0 0 0 0 2 0
text3 0 0 0 0 1 0 0 0 0 0
text4 0 0 0 0 0 0 0 0 0 0
text5 0 0 0 0 0 0 0 0 0 0
text6 0 0 0 0 0 0 0 0 1 0
[ reached max_ndoc ... 1,384 more documents, reached max_nfeat ... 4,453 more features ]Die Document-Feature-Matrix können wir u.a. dazu nutzen, um mit topfeatures() die häufigsten Wörter in den Tweets zu zählen. Hierfür fügen wir einfach die Funktion am Ende der Pipeline hinzu.
tweets$text |>
quanteda::tokens() |>
quanteda::dfm() |>
quanteda::topfeatures() . ! , the " to and a in is
1228 1103 843 827 526 474 472 392 380 372 Leider ist die Liste der Top Features nicht besonders interessant, weil neben Wörtern auch Satzzeichen als Features vorhanden sind.
2.4 Diktionärcodierung
Die diktionärsbasierte Codierung ist ein weit verbreitetes Analyseverfahren, welche sich ebenfalls leicht in quanteda umsetzen lässt. Es enthält eine Reihe von Diktionären, die vor allem für englische Texte gedacht sind, aber auch ein deutsches Diktionär für politische Kommunikation. Diktionäre sind nichts weiter als geordnete Wortlisten, die Diktionärcodierung praktisch eine Erweiterung unserer einfachen Auszählung für einzelne Variablen (s.o.).
Ein Markenzeichen von Trumps Kommunikationsstil ist dier Verwendung des Wortes “sad”. Für einzelne Wörter wie “sad” benötigen wir nicht unbedigt ein Diktionär. Wie bereits bei den Hashtags und @-mentions könnten wir auch hier wieder auf str_count() zurückgreifen. Allerdings wäre hier ein anspruchsvollerer regulärer Ausdruck zu verwenden, weil das Wort “sad” auch Teil anderer Wörter wie “sadistic” ist. Entsprechend würden diese auch gezählt, wenn wir nur str_count(text, "sad") verwenden. Deshalb greifen wir hier auf die Dokument-Feature-Matrix zurück, welche das Wort “sad” als eigenständige Spalte (feature) enthält.
Mit dictionary() können wir uns dann ein simples Diktionär bauen, um die Häufigkeit von Wörtern zu zählen. Dazu müssen wir lediglich eine Liste mit list() erstellen, welche den Namen der Kategorie festlegt sowie die Wörter, die der Kategorie angehören. Nachfolgend erstellen wir zwei Kategorien: negative und positive. Negative enthält lediglich das Wort “sad” (c("sad")), während wir der Kategorie positive zu Illustrationszwecken die zwei Wörter “super” und “fantastic” (c("great", "fantastic"))hinzufügen. Anschließend verwenden wir das Diktionär in dfm_lookup(). Diese Funktion, wie der Name schon verrät, sucht wie häufig die Wörter in einem Diktionär vorkommen.
dict <- quanteda::dictionary(list(negative = c("sad"), positive = c("great", "fantastic")))
dict_coding <- tweets$text |>
quanteda::tokens() |>
quanteda::dfm() |>
quanteda::dfm_lookup(dictionary = dict) |>
as_tibble()
dict_coding# A tibble: 1,390 × 3
doc_id negative positive
<chr> <dbl> <dbl>
1 text1 0 0
2 text2 0 0
3 text3 0 0
4 text4 0 0
5 text5 0 0
# ℹ 1,385 more rowsDas Beispiel zeigt, dass Diktionäre im Kern lediglich Wortlisten darstellen, die einem Konstrukt bzw. Kategorie zugeordnet werden. Hier berechnen wir die Mittelwerte der beiden Variablen.
dict_coding |>
summarise(
m_negative = mean(negative),
m_positive = mean(positive)
)# A tibble: 1 × 2
m_negative m_positive
<dbl> <dbl>
1 0.0158 0.154
Note
Es gibt auch sogenannte off-the-shelf Diktionäre, die von anderen Autoren für die Sentimentanalyse konstruiert wurden. Für das nachfolgende Beispiel verwenden wir das Diktionär von Young und Soroka (2012), das im quanteda Paket mitgeliefert wird. Auch hier müssen wir lediglich das Diktionär in dfm_lookup() eintragen. So können wir noch das Sentiment über den Zeitverlauf pro Urheber darstellen. Hier bilden wir eine neue Variable sentiment, die den Saldo von positiven und negativen Wörtern pro Tweet misst. Diesen zählen wir für den Untersuchungszeitraum nach Monaten aus und erstellen ein Liniendiagramm.
tweets$text |>
quanteda::tokens() |>
quanteda::dfm() |>
quanteda::dfm_lookup(dictionary = data_dictionary_LSD2015) |>
as_tibble() |>
cbind(tweets) |>
group_by(source, created = floor_date(created, unit = "month")) |>
summarise(sentiment = mean(positive - negative, na.rm = T)) |>
ggplot(aes(x = created, y = sentiment, color = source)) +
geom_line()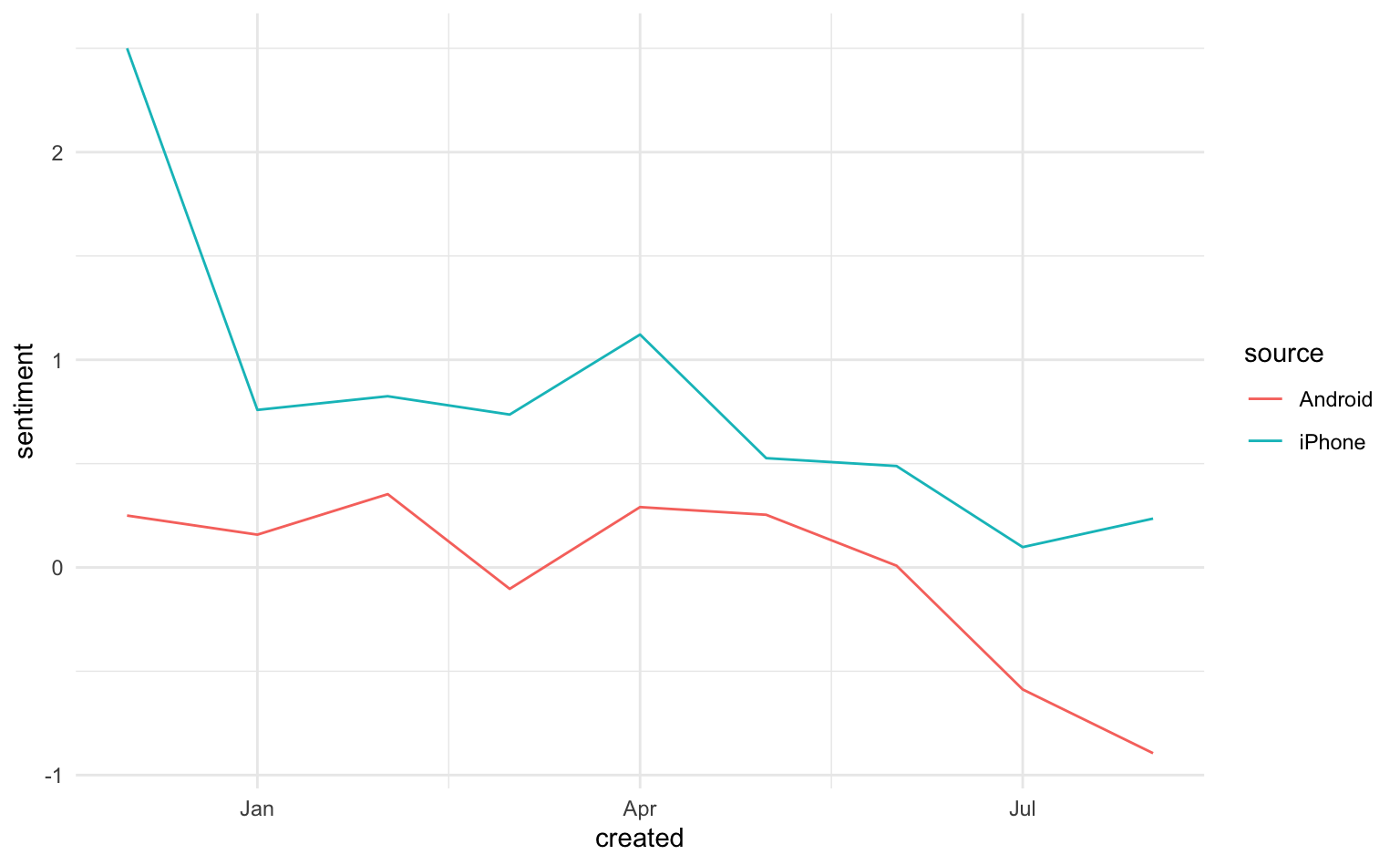
2.5 Textklassifikation mit Deep Learning
Transformer-Modelle können für spezielle Klassifikationsaufgaben trainiert werden, dies ist ein Anwendungsfall von supervised machine learning. Die Plattform Hugging Face enthält eine Vielzahl vortrainierter Modelle, welche für verschiedene Anwendungsfälle kreiert wurden. Nachfolgend nutzen wir wieder eine für diesen Kurs erstellte Funktion, text_classification(), welche es erlaubt, ein vortrainiertes Modell direkt in R zu verwenden. In der Standardeinstellung nutzt die Funktion text_classification() ein Modell, welches für die Sentimentanalyse trainiert wurde.
tweets |>
filter(id %in% c("760246732152311808", "760783130978648064", "761892829434183684")) |>
pull(text) |> # Textspalte nach dem Filtern auswählen
hfapi::text_classification(url = "https://api-inference.huggingface.co/models/distilbert-base-uncased-finetuned-sst-2-english")# A tibble: 3 × 3
NEGATIVE POSITIVE text
<dbl> <dbl> <chr>
1 0.998 0.00204 Hillary Clinton is being badly criticized for her poor perf…
2 0.997 0.00348 Our incompetent Secretary of State, Hillary Clinton, was th…
3 0.976 0.0238 Hillary Clinton raked in money from regimes that horribly o…In den Spalten NEGATIVE und POSITIVE ist nun angegeben, wie sicher sich das Modell bei der jeweiligen Klasse ist. Die Konfidenzwerte sind in allen drei Fällen für NEGATIVE sehr hoch, was angesichts des Inhaltes der Kurznachrichten nicht sonderlich verwunderlich ist.
Wollen wir ein anderes Modell verwenden, müssen wir dieses auf der Hugging Face Plattform recherchieren und dort den Namen des Modells finden, z.B. unitary/toxicbert. Diesen Namen müssen wir an https://api-inference.huggingface.co/models/ anfügen und als URL der Funktion übergeben. Beispielsweise können wir ein auf die Erkennung toxische Inhalte trainiertes Modell mit url = "https://api-inference.huggingface.co/models/unitary/toxic-bert" nutzen. Jedes Modell besitzt eine eigene Informationsseite auf Hugging Face, wo wir Details zum Training und den Anwendungsfällen erfahren. Es gibt nicht nur für Sentiment, sondern auch für Thema, Sprache uvw. eigene Modelle.