library(tidyverse)
theme_set(theme_minimal())1 Datenerhebung
Für die automatische Erhebung von Online-Inhalten mit R gibt es verschiedene Möglichkeiten, die mit unterschiedlichem Aufwand verbunden sind. Manche Daten sind direkt für die Auswertung in R geeignet, z.B. tabellarische Daten wie CSV-Dateien, andere müssen mühsam aus Inhalten extrahiert werden, die für menschliche RezipientInnen aufbereitet sind, z.B. Webseiten. Für manche Plattformen und Datenformate gibt es fertige R-Pakete, für andere müssen wir selbst die Aufbereitung programmieren.
Aufsteigend von der leichtesten zur schwierigsten Umsetzung, natürlich abhängig von der Plattform, die untersucht werden soll, ergibt sich diese Reihe:
- maschinenlesbaren Dateien direkt aus dem WWW einlesen (z.B. CSV-Files)
- fertige R-Pakete für einzelne Plattformen/Anbieter verwenden (z.B. für TikTok)
- über Feeds oder API (Application Programming Interface) standardisierte Daten erhalten
- über Web-Scraping HTML-Inhalte von Websites herunterladen und verarbeiten
- über ferngesteuerte Browser Inhalte erheben oder Screenshots erstellen
- NutzerInnen um Datenspenden bitten
Die Punkte 4, 5 und 6 werden wir nicht behandeln, weil sie einerseits sehr plattformabhängig sind, und andererseits eine sehr tiefgehende Auseinandersetzung mit den technischen und forschungspraktischen Herausforderungen erfordern, die den Rahmen des Seminars sprengen würden. Leider fallen einige sehr populäre Platformen wie Facebook, Instagram und Twitter darunter, die den Forschenden die Erhebung selbst von “öffentlichen” Daten sehr erschweren. Auch fertige R-Pakete für diese Plattformen (Punkt 2) sind häufig von Änderungen durch die Plattformbetreiber betroffen, die schnell dazu führen können, dass diese Pakete obsolet werden. Wir stellen deshalb eine Reihe von Befehlszeilen-Tools vor, die sich auf Grund Populärität und großen Zahl an unterstützenden Entwicklern als relativ robust erwiesen haben.
Zu Beginn laden wir zunächst das tidyverse Paket und setzen ein schöneres Theme für alle Grafiken, die wir erstellen.
1.1 Tabellarische Daten
1.1.1 CSV-Dateien
Am einfachsten ist die Situation, wenn Textdaten bereits in strukturierter maschinenlesbarer Form vorliegen. Im Internet gibt es zahlreiche mehr oder minder seriöse Quellen für solche Daten, etwa auf Kurs-Websites, bei Kaggle, oder auf dieser Workshop-Seite.
Wir haben hier einen Datensatz mit Songtexten von Taylor Swift ausgewählt, der im Rahmen der Tidy Tuesday Reihe für originelle Datenanalysen veröffentlicht wurde. Hier finden sich auch viele andere interessante Datensätze. Der Datensatz liegt direkt als CSV-File vor, das wir in R einlesen und ansehen können.
# Source:
taylor_swift_lyrics <- readr::read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-09-29/taylor_swift_lyrics.csv")
taylor_swift_lyrics# A tibble: 132 × 4
Artist Album Title Lyrics
<chr> <chr> <chr> <chr>
1 Taylor Swift Taylor Swift Tim McGraw "He said the way my blue eye…
2 Taylor Swift Taylor Swift Picture to Burn "State the obvious, I didn't…
3 Taylor Swift Taylor Swift Teardrops on my Guitar "Drew looks at me,\nI fake a…
4 Taylor Swift Taylor Swift A Place in This World "I don't know what I want, s…
5 Taylor Swift Taylor Swift Cold As You "You have a way of coming ea…
# ℹ 127 more rowsDie Songtexte sind in der Spalte Lyrics, zusätzlich gibt es noch Angaben zu Song und Album.
1.1.2 Andere Formate
Manchmal liegen Daten in weniger verbreiteten Formaten wie SPSS oder Stata-Datensätze oder, wie im folgenden Beispiel, als sog. parquet-File vor. Auf der Plattform Hugging Face hat ein Nutzer die Inhalte der Tagesschau-Website per Webscraping (s.u.) heruntergeladen und aufbereitet. Eine kurze Web-Recherche ergab, dass für das Einlesen dieses Datenformats das R-Paket arrow zur Verfügung steht. Dieses laden wir (nachdem wir es installiert haben, was RStudio uns vorschlagen sollte) und öffnen dann die Datei direkt über die URL.
library(arrow)
# Source: https://huggingface.co/datasets/bjoernp/tagesschau-2018-2023
tagesschau_archiv <- arrow::read_parquet("https://huggingface.co/api/datasets/bjoernp/tagesschau-2018-2023/parquet/default/train/0.parquet")
tagesschau_archiv# A tibble: 21,847 × 6
date headline short_headline short_text article link
<chr> <chr> <chr> <chr> <chr> <chr>
1 2023-04-27 Türkei-Wahl in Deutschland… 1,5 Millionen… "Etwa 1,5… "Etwa … /aus…
2 2023-04-27 Bolsonaro bestreitet Verwi… Brasilien "Brasilie… "Brasi… /aus…
3 2023-04-27 Streiten, ob Hilfe wirklic… Afghanistan-P… "Deutschl… "Deuts… /inl…
4 2023-04-27 Republikaner machen Druck … US-Haushaltss… "Die Repu… "Die R… /aus…
5 2023-04-27 Russland plant Schein-Orga… Strategiepapi… "Russland… "Russl… /inv…
# ℹ 21,842 more rowsDer Datensatz enthält über 20.000 Beiträge, und neben dem Veröffentlichungsdatum die Überschriften und Texte der Artikel, je in einer kurzen und langen Fassung.
NoteSchlagzeilen im Zeitverlauf
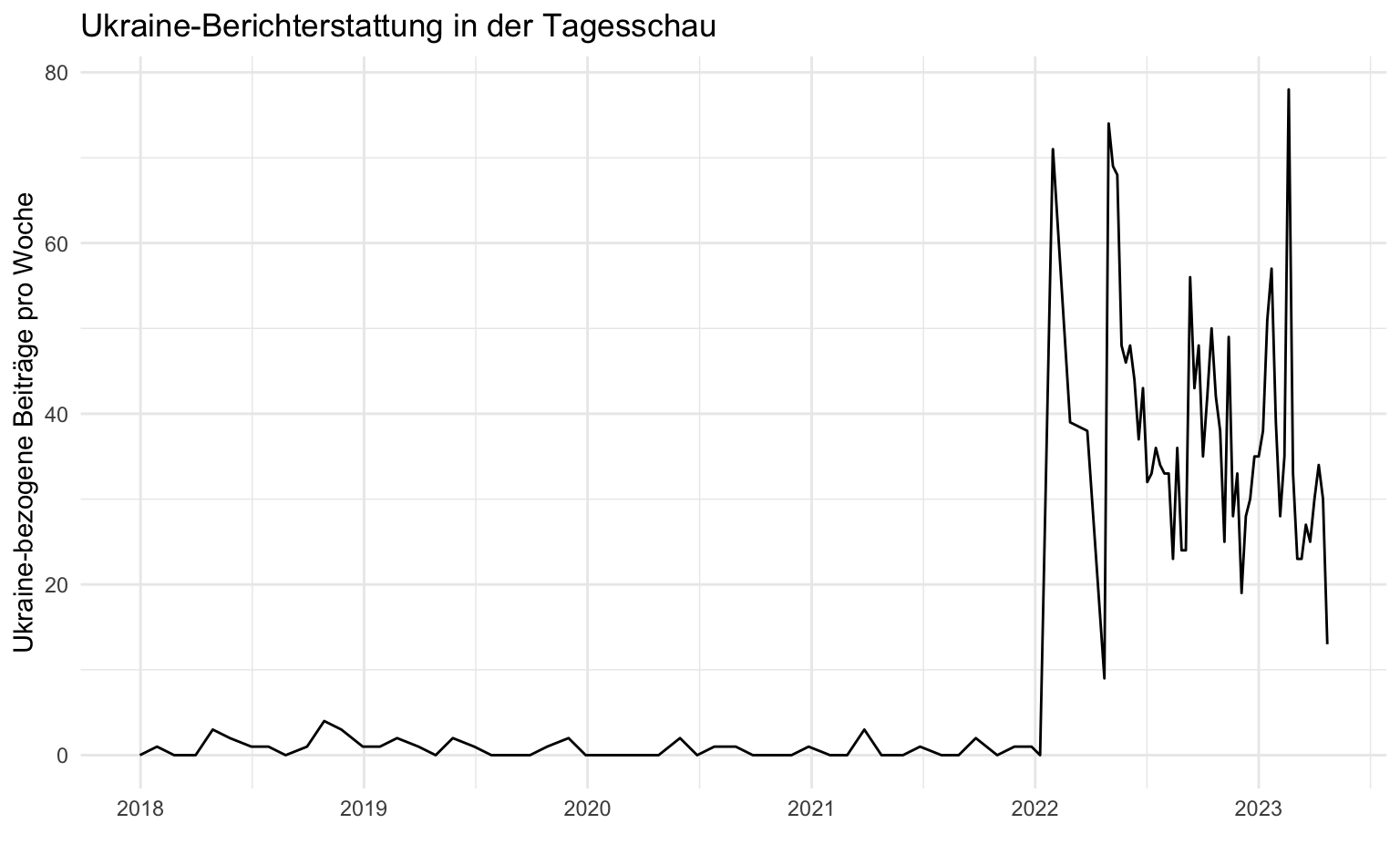
Mit dem nachfolgenden Code zählen wir das Vorkommen von Ukraine in der Spalte short_text des Datensatzes, und erstellen aus der Häufigkeitstabelle ein Liniendiagramm, in dem die Beiträge pro Woche abgetragen werden. Die zentrale Funktion ist str_detect(), mit dem codiert wird, ob ein Begriff im Text vorkommt oder nicht. Dieser Wert wird in der Variable ukraine gespeichert und anschließend wochenweise mit group_by() und summarise() aufsummiert. Die Wochenvariable week wird mit floor_date() erstellt, die jedes Datum umcodiert in den ersten Wochentag der entsprechenden Kalenderwoche.
tagesschau_archiv |>
mutate(
ukraine = str_detect(short_text, "Ukrain|ukrain"),
week = floor_date(as.Date(date), "week")
) |>
group_by(week) |>
summarise(n_ukraine = sum(ukraine)) |>
ggplot(aes(x = week, y = n_ukraine)) +
geom_line() +
scale_x_date(
date_breaks = "1 year",
date_labels = "%Y"
) +
labs(
x = "", y = "Ukraine-bezogene Beiträge pro Woche",
title = "Ukraine-Berichterstattung in der Tagesschau"
)
1.2 Feeds und Web-APIs
Mit Feeds und JSON-APIs stehen seit langem standardisierte Zugriffsmechanismen für Web-Inhalte zur Verfügung. Diese sind mal mehr (RSS-Feeds), mal weniger (JSON) standardisiert: RSS-Feeds haben stets dieselben Spalten wir title oder description, während das JSON-Format syntaktisch zwar immer gleich ist, die enthaltenen Felder aber unterschiedlich sind. Daher müssen wir JSON-Daten immer manuell inspizieren, um relevante Felder zu finden, während Feeds leichter zu verarbeiten sind.
1.2.1 RSS Feeds
Für das Einlesen von Feeds gibt es das tidyRSS Paket mit dem entsprechenden Befehl tidyfeed(), dem wir nur die URL des Feeds übergeben müssen. Hier nehmen wir die Schlagzeilen von SPIEGEL Online.
library(tidyRSS)
spiegel <- tidyRSS::tidyfeed("https://www.spiegel.de/schlagzeilen/tops/index.rss")
spiegel |>
glimpse()Rows: 21
Columns: 14
$ feed_title <chr> "DER SPIEGEL - Schlagzeilen – Tops", "DER SPIEGEL…
$ feed_link <chr> "https://www.spiegel.de/", "https://www.spiegel.d…
$ feed_description <chr> "Deutschlands führende Nachrichtenseite. Alles Wi…
$ feed_language <chr> "de", "de", "de", "de", "de", "de", "de", "de", "…
$ feed_pub_date <dttm> 2025-10-27 08:36:17, 2025-10-27 08:36:17, 2025-1…
$ feed_last_build_date <dttm> 2025-10-27 08:36:17, 2025-10-27 08:36:17, 2025-1…
$ feed_category <chr> "Ausland", "Ausland", "Ausland", "Ausland", "Ausl…
$ item_title <chr> "Argentinien: Präsident Javier Milei galt als erl…
$ item_link <chr> "https://www.spiegel.de/ausland/argentinien-praes…
$ item_description <chr> "Entgegen aller Vorhersagen ist Javier Milei der …
$ item_pub_date <dttm> 2025-10-27 06:26:00, 2025-10-27 05:26:00, 2025-1…
$ item_guid <chr> "https://www.spiegel.de/ausland/argentinien-praes…
$ item_enclosure <list> [], [], [], [], [], [], [], [], [], [], [], [], …
$ item_category <chr> "Ausland", "Politik", "Politik", "Wirtschaft", "W…Interessant sind für uns vor allem die Item-Variablen, etwa item_title oder item_description, die sich auf die einzelnen Beiträg beziehen. Ebenso gibt es wieder Metadaten wie etwas das Publikationsdatum oder die Kategorie.
1.2.2 JSON-APIs
Für das Einlesen von JSON-Daten gibt es das jsonlite Paket mit der fromJSON() Funktion. Als Beispiel rufen wir die offizielle JSON-API der Tagesschau auf, die hier dokumentiert ist. Die eigentlichen Nachrichten sind im Feld news, das wir in einen Datenframe konvertieren können.
library(jsonlite)
# Source: https://github.com/AndreasFischer1985/tagesschau-api
tagesschau_news <- jsonlite::fromJSON("https://www.tagesschau.de/api2u/news")$news |>
as_tibble()
tagesschau_news# A tibble: 58 × 24
sophoraId externalId title date teaserImage$copyright tags updateCheckUrl
<chr> <chr> <chr> <chr> <chr> <lis> <chr>
1 aktuellolde… 1c7cf18c-… Unfa… 2025… Fotolia, Fotolia <df> https://www.t…
2 heizoel136 f45b7271-… Heiz… 2025… IMAGO, Rolf Poss <df> https://www.t…
3 swr-bw-news… tagesscha… BW-N… 2025… IMAGO, Passion2Press… <df> https://www.t…
4 regionflens… b22ae0d9-… Müll… 2025… Colourbox, - <df> https://www.t…
5 braunschwei… 3233c03a-… Unfa… 2025… picture alliance/dpa… <df> https://www.t…
# ℹ 53 more rows
# ℹ 21 more variables: teaserImage$alttext <chr>, $imageVariants <df[,12]>,
# $type <chr>, $title <chr>, tracking <list>, topline <chr>,
# brandingImage <df[,5]>, details <chr>, detailsweb <chr>, shareURL <chr>,
# geotags <list>, regionId <int>, regionIds <list>, breakingNews <lgl>,
# type <chr>, firstSentence <chr>, streams <df[,4]>, alttext <chr>,
# copyright <chr>, ressort <chr>, comments <chr>Auch hier gibt es zahlreiche Spalten, u.a. title oder date.
NoteBildergallerie aus Sportmeldungen
Über die Tagesschau-API lassen sich auch spezifische Ressorts oder regionale Nachrichten herausfiltern. Hier speichern wir zunächst die Sportnachrichten als Datenframe ab. Anschließend extrahieren wir die Liste von Teaser-Bildern im kleinsten Format, löschen fehlende Einträge und verarbeiten die ersten 15 Bilder wieder mit dem Paket magick weiter, mit dessen Hilfe die Bilder eingelesen und zu einem Bildraster zusammengeführt werden.
sport_news <- jsonlite::fromJSON("https://www.tagesschau.de/api2u/news?ressort=sport")$news |>
as_tibble()
sport_news$teaserImage$imageVariants$`1x1-144` |>
na.omit() |>
head(15) |>
magick::image_read() |>
magick::image_montage(tile = 5, geometry = "x120+2+2")
1.3 Kommandozeilen-Tools
1.3.1 yt-dlp
yt-dlp ist ein Kommandozeilen-Programm zum Herunterladen von Videos und Audiodateien von verschiedenen Webseiten, darunter Youtube oder die deutschen Mediatheken, aber auch TikTok.
Mit Hilfe des yt-dlp-Befehls können wir zum Beispiel TikToks der Tagesschau herunterzuladen. Wir setzen einige Optionen, um etwa Meta-Daten des Videos zu erhalten, passende Dateinamen zu setzen oder angefangene Downloads fortzusetzen. Wir laden nun die letzten 3 Videos, welches auf dem TikTok-Kanal der Tagesschau veröffentlicht wurde, herunter. Dazu müssen wir drei Argumente anpassen:
--playlist-end: Gibt die Anzahl der Videos für den Download an. Wir verwenden hier3, was bedeutet, dass wir die letzten 3 Videos herunterladen.-P: Setzt einen Downloadpfad, d.h. in welchem Ordner die Videos gespeichert werden sollen. Da wir den Kanal der Tagesschau untersuchen, schreiben wir die Videos einfach in einen Ordner mit dem Namendata/tagesschau. Wenn dieser Ordner noch nicht exisitert, erstelltyt-dlpdiesen Ordner.- Am Ende des Aufrufs geben wir die URL an. In unserem Fall
https://www.tiktok.com/@tagesschau/.
yt-dlp -w --write-info-json --write-thumbnail --no-write-playlist-metafiles -c -o "%(id)s.%(ext)s" --restrict-filenames --playlist-end 3 -P data/tagesschau "https://www.tiktok.com/@tagesschau/" Nachdem wir die Videos heruntergeladen haben, erhalten wir eine mp4-Datei, ein Thumbnail-Bild sowie weitere Meta-Daten im JSON-Format. Das Thumbnail könnten wir wieder mittels magick darstellen, stattdessen wollen wir uns aber die Meta-Daten anschauen. Hier hilft wieder das jsonlite Package. Da bei TikTok sehr viele app- und videospezifische Metadaten mitgeliefert werden, entfernen wir diese Spalten am Ende, um einen etwas aufgeräumteren Datensatz zu erhalten.
tt_metadata <- list.files("data/tagesschau", pattern = "*.json", full.names = T) |>
map(jsonlite::fromJSON) |>
map_df(unlist) |>
select(-starts_with(c("formats", "http_headers")))
tt_metadata# A tibble: 3 × 67
id channel channel_id uploader uploader_id channel_url uploader_url track
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 756554… tagess… MS4wLjABA… tagessc… 6657771415… https://ww… https://www… Orig…
2 756556… tagess… MS4wLjABA… tagessc… 6657771415… https://ww… https://www… Orig…
3 756565… tagess… MS4wLjABA… tagessc… 6657771415… https://ww… https://www… Orig…
# ℹ 59 more variables: artists <chr>, duration <chr>, title <chr>,
# description <chr>, timestamp <chr>, view_count <chr>, like_count <chr>,
# repost_count <chr>, comment_count <chr>, thumbnails.id1 <chr>,
# thumbnails.id2 <chr>, thumbnails.id3 <chr>, thumbnails.url1 <chr>,
# thumbnails.url2 <chr>, thumbnails.url3 <chr>, thumbnails.preference1 <chr>,
# thumbnails.preference2 <chr>, thumbnails.preference3 <chr>,
# webpage_url <chr>, webpage_url_basename <chr>, webpage_url_domain <chr>, …Nachdem wir die Daten geladen haben, können wir uns etwa Titel, Dauer, oder Metriken wie die Anzahl der Kommentare oder Aufrufe des TikTok-Videos anzeigen lassen.
tt_metadata |>
select(title, duration, ends_with("count"))# A tibble: 3 × 6
title duration view_count like_count repost_count comment_count
<chr> <chr> <chr> <chr> <chr> <chr>
1 Die verbotene kurdi… 33 341600 11000 1743 882
2 Die französische Po… 219 1200000 70900 6747 694
3 Wer es schafft, mit… 95 62700 1850 29 65 1.3.2 Exkurs: Audioinhalte mit Whisper transkribieren
Wollen wir nun TikTok-Videos analysieren, kann es sinnvoll sein, diese zu transkribieren, da sich Text besser für weitere Analyseschritte eignet. Dieser Schritt lässt sich mit whisper von OpenAI, der Firma hinter ChatGPT, automatisiert umsetzen.
Hierfür nutzen wir whisper-ctranslate2, um den Inhalt unseres TikTok-Videos zu transkribieren. Wir geben noch die Modellgröße mit der Option --model an. Wir benutzen hier das “mittlere” (= medium) Modell. Wir könnten einfach den Pfad angeben, bspw. “tagesschau/das_ist_ein_video.mp4” oder mit dem Platzhalter *.mp4 alle entsprechenden Videos im Ordner transkribieren lassen.
whisper-ctranslate2 --model medium tagesschau/*.mp4Die TSV-Datei enthält Zeitstempel, sowie das Transkript der Audiospur, welche wir mit read_tsv() in R importieren können.
Hausaufgabe
Schauen Sie sich die Grafik zum Inhalt der Tagesschau-Schlagzeilen erneut an. Erstellen Sie die gleiche Grafik für einen anderen Suchbegriff.
Machen Sie sich mit der Tagesschau-API vertraut. Erstellen Sie die als Beispiel dargestellte Bildergallerie für ein anderes Ressort oder ein Bundesland.
Laden Sie die Videos eines beliebigen TikTok-Accounts herunter. Berechnen sie die durchschnittliche Anzahl der Kommentare, Aufrufe und Likes der Videos.