library(tidyverse)
theme_set(theme_minimal())6 Aggregation und Linkage-Analyse
Die Verknüpfung von Befragungs- und digitalen Verhaltensdaten erfolgt im Rahmen einer Linkage-Analyse. Hier gibt es zwei Typen: Entweder erfolgt die Verknüpfung der einzelnen Datensätze unmittelbar während der Datenerhebung (ex ante linkage) oder sie erfolgt nach Abschluss der Datenerhebung (ex post linkage). Hier möchten wir den ex post Linkage betrachten, da dieser Fall am typischsten ist.
Wir laden zunächst die notwendigen Pakete und setzen ein minimalistisches Theme theme_minimal()für unsere Plots.
6.1 Grundlagen zu Linkage
Im untenstehenden Beispiel geht es um eine ereignisbasierten Experience Sampling Studie mit getrackter TikTok- und Instagram-Nutzung. Das heißt, die Fragebögen wurden automatisch beim Schließen der TikTok-App ausgelöst. Die Datensätze zum zugehörigen Paper sind öffentlich im Open Science Framework verfügbar. Es gibt einen Datensatz für die Vorbefragung aus SoSci Survey und jeweils zwei ESM- und Tracking-Datensätze aus der Experience-Sampling-App movisensXS. Anhand dieser schauen wir uns grundlegend an, welche Schritte und “Zutaten” beim Verknüpfen wichtig sind.
Eine weitere Besonderheit: Längsschnittsdaten, zu denen ESM- und Tracking-Daten zählen, liegen meist im Long Format vor, bei dem jede Beobachtung (z.B. eine Nutzungsepisode) eine eigene Zeile hat. Eine Person erscheint also in mehreren Zeilen. Vor- und Nachbefragungen liegen als Querschnittsdaten im Wide Format vor, in dem jede Person genau eine Zeile hat.
6.1.1 Voraussetzung: Unique Identifier/Teilnahme-ID
Jede Linkage-Analyse braucht mindestens eine Variable, die in allen Datensätzen gleich heißt und eindeutig für jeden Teilnehmenden ist – in Befragungsstudien ist das meist die Teilnahme-ID. Kommen Datensätze aus unterschiedlichen Quellen (z.B. movisensXS und SoSciSurvey), müssen wir die Teilnahme-ID oft erst vereinheitlichen. clean_names() sorgt dafür, dass alle Variablennamen einheitlich kleingeschrieben sind. Da es zwei Spalten gab, die Teilnahmecodes entweder für TikTok oder für Instagram ausgespielt haben, liegen die Teilnahme-IDs ebenfalls in separaten Spalten. coalesce() fasst die beiden Spalten zu einer einzigen zusammen.
pre_raw <- read_tsv("data/presurvey_disengagement.tsv")
pre <- pre_raw |>
rename(
app = IV01_01,
participant_tiktok = ON10,
participant_insta = ON11,
sd_age = IN06_01,
sd_gender = SD01
) |>
janitor::clean_names() |>
mutate(participant = coalesce(participant_tiktok, participant_insta))6.1.2 Gleich aufgebaute Datensätze aufeinander stapeln
Die ESM-Daten liegen in diesem Fall als zwei separate Datensätze vor – einer für Instagram, einer für TikTok. Da beide dieselbe Variablenstruktur haben und keine Teilnahme-ID doppelt vorkommt, können wir sie einfach untereinander stapeln. bind_rows() addiert die Zeilen – im Unterschied zu Joins, die Datensätze anhand einer Schlüsselvariable nebeneinander verbinden (siehe unten).
esm_insta <- read_tsv("data/disengagement_instagram.tsv") |>
filter(Participant > 10) |>
mutate(
duration_sr = duration_hours / 60 + duration_minutes,
app = "Instagram"
) |>
janitor::clean_names()
esm_tiktok <- read_tsv("data/disengagement_tiktok.tsv") |>
filter(Participant > 9) |>
mutate(
duration_sr = duration_hours / 60 + duration_minutes,
app = "TikTok"
) |>
janitor::clean_names()
esm_combined <- bind_rows(esm_insta, esm_tiktok)
# Zur Kontrolle: Zeilenanzahl addiert sich
nrow(esm_insta)[1] 2833nrow(esm_tiktok)[1] 683nrow(esm_combined)[1] 3516Nach dem Filtern auf vollständige ESM-Fragebögen, ergibt sich der finale ESM-Datensatz.
esm_complete <- esm_combined |>
filter(form == "Daily ESM" & is.na(missing)) |>
arrange(participant)Dasselbe machen wir mit den Tracking-Daten.
tracking_instagram <- read_tsv("data/tracking_instagram.tsv")
tracking_tiktok <- read_tsv("data/tracking_tiktok.tsv")
tracking_complete <- bind_rows(tracking_instagram, tracking_tiktok)6.2 Datensätze auf gleicher Ebene verbinden
Wir möchten nun die Tracking mit den ESM-Daten verbinden und uns exemplarisch die getrackte vs. selbstberichtete Nutzungsdauer anschauen. Wir transformieren dazu die aufgezeichnete Dauer in numerische Form, um mit ihr rechnen zu können.
tracking_complete <- tracking_complete |>
mutate(duration_tracking = as.numeric(duration))
glimpse(tracking_complete)Rows: 5,415
Columns: 6
$ participant <dbl> 1203, 1203, 1204, 1204, 1204, 1204, 1204, 1204, 1204…
$ start_time <dttm> 2024-09-23 20:05:40, 2024-09-23 23:14:15, 2024-09-2…
$ duration <dbl> 0.36666667, 0.11666667, 0.68333333, 0.73333333, 0.08…
$ app <chr> "com.instagram.android", "com.instagram.android", "c…
$ end_time <dttm> 2024-09-23 18:06:02, 2024-09-23 21:14:22, 2024-09-2…
$ duration_tracking <dbl> 0.36666667, 0.11666667, 0.68333333, 0.73333333, 0.08…Nun erstellen wir ein Objekt mit der Anzahl an getrackten Episoden sowie ihrer durchschnittlichen Länge. Da wir dies für jeden Teilnehmenden tun möchten, müssen wir zunächst gruppieren nach Teilnehmenden mit group_by() und bilden dann pro Teilnehmendem Summen und kalkulieren die durchschnittliche Dauer einer Nutzungsepisode pro Person. Das bezeichnet man als Aggregieren.
tracking_summary <- tracking_complete |>
group_by(participant) |>
summarise(
n_tracking = n(),
mean_duration_tracking = mean(duration_tracking, na.rm = TRUE)
)
glimpse(tracking_summary)Rows: 121
Columns: 3
$ participant <dbl> 201, 211, 215, 217, 222, 223, 228, 230, 232, 23…
$ n_tracking <int> 17, 9, 8, 156, 5, 60, 6, 17, 12, 7, 11, 18, 20,…
$ mean_duration_tracking <dbl> 1.6617647, 1.1222222, 1.1854167, 3.5263889, 9.2…esm_summary <- esm_complete |>
group_by(participant) |>
summarise(
n_surveys = n(),
app_esm = first(app),
mean_duration_selfreport = mean(duration_sr, na.rm = TRUE)
)
glimpse(esm_summary)Rows: 123
Columns: 4
$ participant <dbl> 201, 211, 215, 217, 222, 223, 228, 230, 234, …
$ n_surveys <int> 12, 7, 7, 29, 4, 27, 5, 11, 4, 8, 17, 12, 2, …
$ app_esm <chr> "TikTok", "TikTok", "TikTok", "TikTok", "TikT…
$ mean_duration_selfreport <dbl> 2.000000, 3.142857, 5.571429, 13.966092, 12.5…Jetzt können wir die Tracking-Daten mit den ESM-Daten über unseren Unique Identifier participant verbinden. Die Wahl des Join-Befehls ist inhaltlich und methodisch motiviert:
left_join() behält alle Personen aus dem linken Datensatz, auch wenn sie keine ESM-Daten haben. Fehlende Werte erscheinen als NA.
tracking_summary_left <- tracking_summary |>
left_join(esm_summary, by = "participant")
nrow(tracking_summary_left)[1] 121inner_join() behält nur Personen, die in beiden Datensätzen vorkommen. Hier fallen zwei Personen raus, weil nur einer der beiden Datensätze für sie vorliegt.
tracking_summary_inner <- tracking_summary |>
inner_join(esm_summary, by = "participant")
nrow(tracking_summary_inner)[1] 119anti_join() zeigt, wer im inner_join verloren geht. Das kann hier nützlich zur Kontrolle sein.
anti_join(tracking_summary, esm_summary, by = "participant")# A tibble: 2 × 3
participant n_tracking mean_duration_tracking
<dbl> <int> <dbl>
1 232 12 5.39
2 1212 100 5.61Wir entscheiden uns für inner_join(), weil wir nur Personen analysieren wollen, bei denen sowohl Tracking- als auch ESM-Daten vorliegen. Den join können wir auch direkt mit weiteren Transformationsschritten verbinden. Da wir uns im Anschluss direkt anschauen möchten, wie groß der Anteil an ESM-Fragebögen pro getrackte Episode – gesamt und nach App - ist, berechnen wir den Anteil noch in derselben Pipe.
tracking_summary_filtered <- tracking_summary |>
inner_join(esm_summary, by = "participant") |>
mutate(share_esm_tracking = n_surveys / n_tracking)
glimpse(tracking_summary_filtered)Rows: 119
Columns: 7
$ participant <dbl> 201, 211, 215, 217, 222, 223, 228, 230, 234, …
$ n_tracking <int> 17, 9, 8, 156, 5, 60, 6, 17, 7, 11, 18, 20, 5…
$ mean_duration_tracking <dbl> 1.6617647, 1.1222222, 1.1854167, 3.5263889, 9…
$ n_surveys <int> 12, 7, 7, 29, 4, 27, 5, 11, 4, 8, 17, 12, 2, …
$ app_esm <chr> "TikTok", "TikTok", "TikTok", "TikTok", "TikT…
$ mean_duration_selfreport <dbl> 2.000000, 3.142857, 5.571429, 13.966092, 12.5…
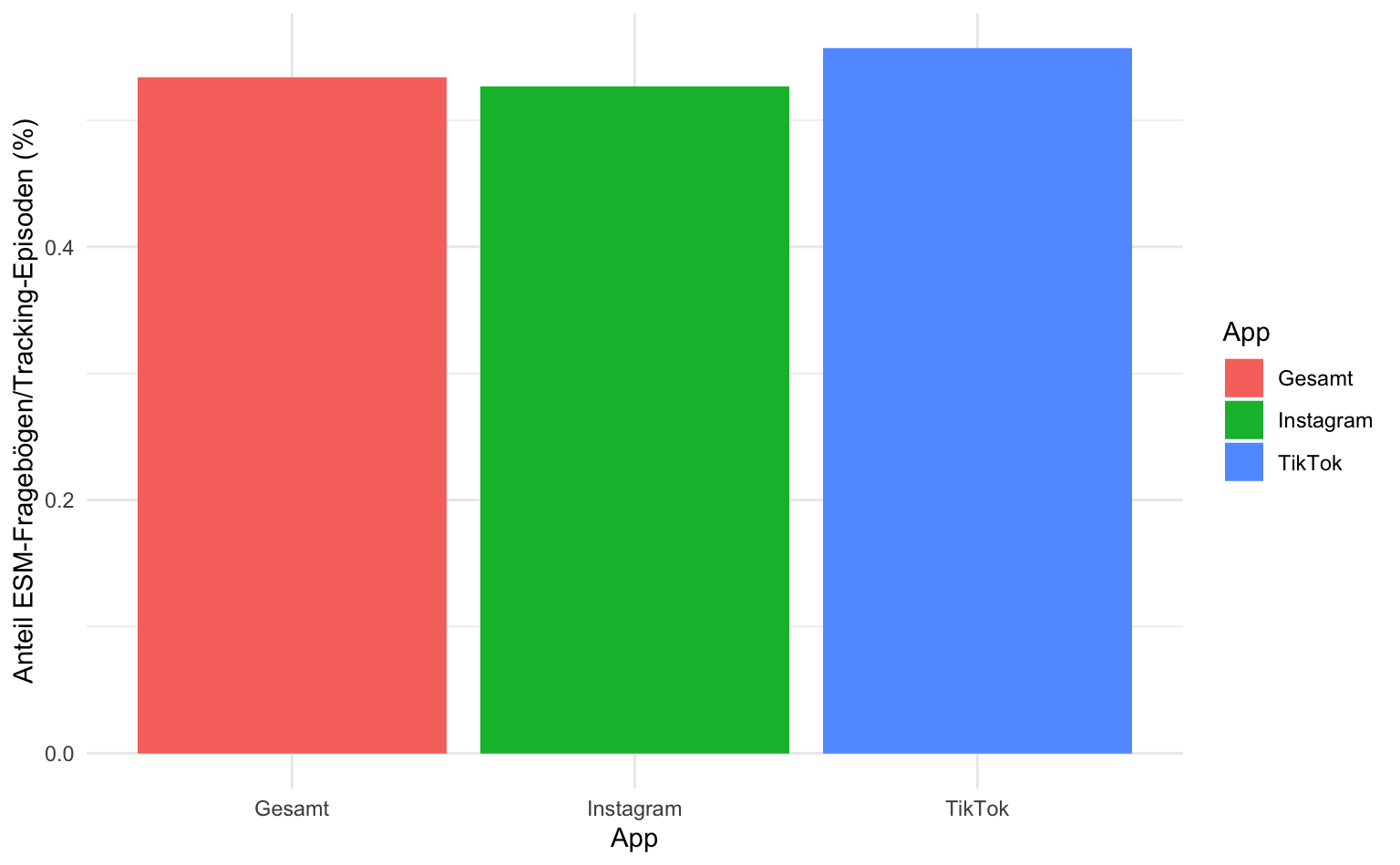
$ share_esm_tracking <dbl> 0.7058824, 0.7777778, 0.8750000, 0.1858974, 0…Zur Veranschaulichung visualisieren wir diese Anteile in einem Histogramm, das sowohl den durchschnittlichen Gesamtanteil an ESM-Fragebögen an getrackter Nutzung darstellt sowie diesen für Instagram und TikTok getrennt berechnet. Hier kommt bind_rows() erneut zum Einsatz, um die Tracking-Daten für Instagram und TikTok zu stapeln und eine weitere Gruppe “Gesamt” hinzuzufügen. Indem wir tracking_summary_filtered mit sich selbst stapeln und dabei app_esm auf “Gesamt” setzen, entsteht eine dritte Gruppe, die alle Personen enthält – unabhängig von der App. So kann summarise() in einem einzigen Schritt sowohl app-spezifische Mittelwerte als auch den Gesamtmittelwert über alle Personen berechnen.
share_summary <- tracking_summary_filtered |>
bind_rows(tracking_summary_filtered |> mutate(app_esm = "Gesamt")) |>
group_by(app_esm) |>
summarise(mean_share = mean(share_esm_tracking, na.rm = TRUE))
ggplot(share_summary, aes(x = app_esm, y = mean_share, fill = app_esm)) +
geom_col() +
labs(
x = "App",
y = "Anteil ESM-Fragebögen/Tracking-Episoden (%)",
fill = "App"
)
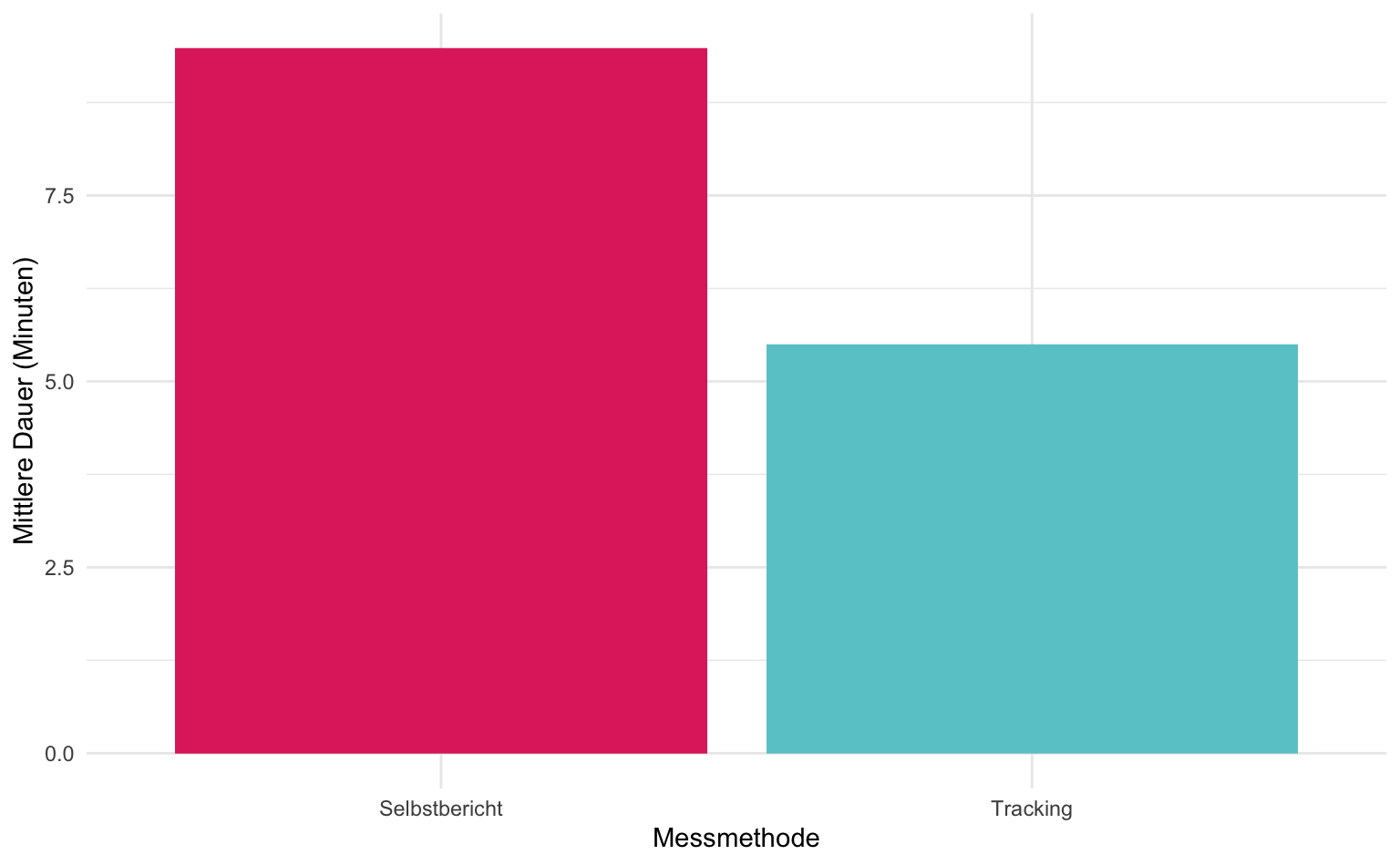
Wir können uns außerdem im Durchschnitt anschauen, inwiefern sich die selbstberichtete Dauer einer Nutzungsepisode deskriptiv zu der getrackten unterscheidet.
means <- tracking_summary_filtered |>
summarise(
tracking = mean(mean_duration_tracking, na.rm = TRUE),
selfreport = mean(mean_duration_selfreport, na.rm = TRUE)
)
ggplot(means) +
geom_col(aes(x = "Tracking", y = tracking), fill = "#69C9D0") +
geom_col(aes(x = "Selbstbericht", y = selfreport), fill = "#E1306C") +
labs(
x = "Messmethode",
y = "Mittlere Dauer (Minuten)"
)
Zuletzt möchten wir einen Datensatz erstellen, der zusätzlich neben der Vorbefragung auch die aggregierte Anzahl an Fragebögen enthält sowie die durchschnittliche Länge einer Instagram oder TikTok-Nutzungsepisode (z.B. wenn wir unsere Daten auf Personenebene analysieren wollen).
Bevor wir nun ‘joinen’ oder ‘matchen’, müssen wir also zunächst beide Datensätze auf die Personenebene “hochaggregieren”. Das bedeutet, wir erstellen aus einem Situationsdatensatz im long format einen Querschnittsdatensatz mit jeweils einer Zeile pro Person. Das haben wir oben bereits gemacht als wir die Nutzungsepisoden pro Teilnehmendem gezählt sowie die durchschnittliche Länge aller Nutzungsepisoden pro Teilnehmendem berechnet haben. Vor- oder Nachbefragungen liegen bereits als Querschnittsdatensatz vor. Bei ihnen bräuchten wir diesen Schritt entsprechend nicht.
Möchten wir zwei Datensätze auf Personenebene (bzw. zwei Querschnittsdatensätze) verbinden, können wir sie, wieder einfach mithilfe von left_join() verbinden. Da es in diesem Fall viele NA-Fälle gibt, filtern wir diese noch zum Schluss heraus. Sind wir uns im Vornherein sicher, dass wir diese NA-Fälle ausschließen möchten, hätten wir hier auch direkt inner_join() nehmen können.
pre_complete <- left_join(pre, tracking_summary_filtered, by = "participant")
glimpse(pre_complete)Rows: 708
Columns: 12
$ app <chr> NA, "Instagram", "Instagram", "Instagram", "I…
$ participant_tiktok <dbl> NA, NA, NA, NA, NA, NA, 210, NA, NA, NA, NA, …
$ participant_insta <dbl> NA, 1217, 1212, 1220, NA, 1211, NA, 1213, NA,…
$ sd_gender <dbl> NA, 1, 1, 2, 1, 1, 1, 3, NA, 1, NA, 2, 2, 2, …
$ sd_age <dbl> 36, 33, 31, 39, 49, 27, 38, 39, NA, 22, NA, 3…
$ participant <dbl> NA, 1217, 1212, 1220, NA, 1211, 210, 1213, NA…
$ n_tracking <int> NA, 155, NA, NA, NA, NA, NA, 37, NA, 227, NA,…
$ mean_duration_tracking <dbl> NA, 2.075699, NA, NA, NA, NA, NA, 8.798649, N…
$ n_surveys <int> NA, 41, NA, NA, NA, NA, NA, 17, NA, 36, NA, N…
$ app_esm <chr> NA, "Instagram", NA, NA, NA, NA, NA, "Instagr…
$ mean_duration_selfreport <dbl> NA, 3.317073, NA, NA, NA, NA, NA, 14.297059, …
$ share_esm_tracking <dbl> NA, 0.2645161, NA, NA, NA, NA, NA, 0.4594595,…pre_complete <- pre_complete |>
filter(!is.na(app_esm))6.2.1 Datensätze in unterschiedlichen Formaten verbinden
Möchten wir Daten auf Situationsebene mit Daten auf Personenebene verbinden, aber die Daten auf Situationsebene analysieren, während wir gleichzeitig Informationen auf Personenebene haben (z.B. wenn die Personenvariable Geschlecht das Nutzungsverhalten auf der Situationsebene vorhersagen soll), hängen wir meist die Personendaten zu jeder einzelnen Situation des jeweiligen Teilnehmenden an. Der Datensatz bleibt im long format. Hierzu nutzen wir in der Regel left_join() über die Verlinkungs-Variable (hier: participant), sodass nur Personen behalten werden, für die situative Daten vorliegen. Als generelle Faustregel nehmen wir also die Daten auf der höheren Ebene, die nur einmal für diese Ebene vorliegen, und heften sie an jede Zeile der unteren Ebene an. In späteren Analysen werden diese Personendaten dann nur einmal pro participant verwendet.
complete_long <- esm_complete |>
left_join(pre, by = "participant")6.3 Ausblick: Getrackte Mediennutzungssessions zu passenden ESM-Fragebögen ordnen
In manchen Studien reicht ein einfacher Join über die Teilnahme-ID nicht aus – zum Beispiel wenn man wissen möchte, welche Tracking-Episode unmittelbar vor einem ESM-Fragebogen lag. Dafür gibt es in dplyr das join_by()-Argument mit closest(), das den zeitlich nächstgelegenen Match findet.
Oftmals sind Nutzungsepisoden unterbrochen, und man muss daher bedeutsame Bezugspunkte identifizieren, auf die sich die ESM-Fragen fokussieren. Hier wurde sich immer für die zuletzt zurückliegende entschieden.
Drei Bedingungen müssen erfüllt sein: alle Zeilen müssen dieselbe Teilnahme ID haben, trigger_time des ESM-Fragebogens muss größer oder gleich sein wie end_time der getrackten Nutzung, und durch closest() wird von allen Zeilen, die Bedingung 1 und 2 erfüllen, nur die nächstgelegene behalten – also die, wo trigger_time am knappsten nach end_time liegt. Nachdem wir das by-Argument spezifiziert haben, verbinden wir die ESM-Daten mit den Tracking-Episoden.
Zusätzlich berechnen wir die Latenz in Sekunden (latency), also wie viele Sekunden zwischen dem Ende der Nutzungsepisode end_time und dem ESM-Trigger trigger_time lagen. Wir setzen duration_tracking auf NA, wenn die Latenz mehr als 600 Sekunden (= 10 Minuten) beträgt, die Episode liegt dann gemäß gesetzter Definitionskriterien zu weit zurück.
by <- join_by(participant, closest(trigger_time >= end_time))
esm_complete <- complete_long |>
distinct(participant, trigger_time, .keep_all = TRUE) |>
left_join(tracking_complete, by) |>
mutate(latency = as.numeric(difftime(trigger_time, end_time, units = "secs"))) |>
mutate(duration_tracking = if_else(latency > 600, NA, duration_tracking))
esm_complete |>
select(participant, end_time, trigger_time, latency, duration_tracking) |>
print(n = 5)# A tibble: 1,890 × 5
participant end_time trigger_time latency duration_tracking
<dbl> <dttm> <dttm> <dbl> <dbl>
1 201 2024-09-20 17:09:47 2024-09-20 17:09:48 1 0.05
2 201 2024-09-20 17:30:44 2024-09-20 17:30:45 1 0.233
3 201 2024-09-21 11:28:09 2024-09-21 11:28:10 1 0.1
4 201 2024-09-21 11:59:01 2024-09-21 11:59:02 1 0.867
5 201 2024-09-23 10:11:34 2024-09-23 10:11:35 1 0.25
# ℹ 1,885 more rows6.4 Hausaufgabe
Für die Hausaufgabe nutzen wir verschiedene Teildatensätze einer Linkage-Studie, in der Teilnehmende Fragen zu ihrer Spotify-Nutzung beantworteten und zudem ihre Hörverlaufe gespendet haben. Alle Daten wurden in SoSciSurvey erhoben.
Aufgabe 1: Laden Sie den Hörverlauf spotify_history.tsv und den Befragungsdatensatz spotify_respondents.tsv und inspizieren Sie ihre Struktur. In welchem Format liegen die Datensätze vor? Wie viele Teilnehmende und wie viele Höreinträge enthält der Hörverlauf?
Aufgabe 2: Aggregieren Sie den Hörverlauf auf Personenebene (Anzahl gehörter Songs pro Person). Verbinden Sie dieses Objekt anschließend mit dem Befragungsdatensatz. Welchen Join-Befehl wählen Sie – und warum?
Aufgabe 3: Erstellen Sie eine Tagesvariable aus dem Zeitstempel mit lubridate::as.Date() und visualisieren Sie die Anzahl aktiver Nutzender sowie die Gesamtanzahl gehörter Songs pro Tag.
Aufgabe 4 (optional): Laden Sie spotify_songs.tsv und verbinden Sie diesen Datensatz mit dem Hörverlauf spotify_history anhand des unique identifiers des tracks. Achtung! Diese ID-Variablen sind unterschiedlich in den Datensätzen benannt. Schauen Sie sich zunächst die Variablennamen an. Es sollen alle Höreinträge erhalten bleiben. Welchen Join-Befehl wählen Sie?