library(lme4)
library(marginaleffects)
library(tidyverse)
library(report)
theme_set(theme_minimal())7 Mehrebenenanalyse mit dem REWB-Modell
ESM- und Tracking-Daten liegen in der Regel geschachtelt vor. Das heißt, alle Teilnehmenden haben mehrere Messzeitpunkte. Dadurch entstehen zwei Ebenen: die Situationsebene und die Personenebene. Wir schauen uns hier exemplarisch an, wie man lineare Zusammenhänge und Unterschiede mit dieser Art von Daten schätzen kann. Wir stellen dafür ein vielgenutztes Mehrebenen-Modell vor: das Random-Effects-Within-Between Modell (REWB-Modell). Dieses Modell wird u.a. auch mit einem anderen Datensatz in der Vorlesung “Angewandte Analyseverfahren” vorgestellt.
7.1 Pakete und Daten
Wir laden zunächst die notwendigen R-Pakete. Für die Multilevel-Analysen das lme4-Paket, für die Modellvorhersagen marginaleffects. Wie immer laden wir tidyverse und report und setzen ein schöneres Theme.
Als Datensatz verwenden wir wieder Teildatensätze einer Linkage-Studie über Nutzung und Erleben von Musikstreaming auf Spotify. Der für die Übung zugeschnittene Datensatz ist im sog. Langformat, d.h. die Daten aller beantworteten ESM-Fragebögen bzw. Situationen werden aufeinander gestapelt — dementsprechend gibt es n Personen und t Situationen. Die Personen sind mit der Variable participant_id gekennzeichnet. Stabile Personenmerkmale wie Alter sind an den Situationsdatensatz angefügt und wiederholen sich entsprechend pro Person (siehe Übung zur Linkage-Analyse).
d_spotify <- read_tsv("data/spotify_rewb.tsv")
d_spotify# A tibble: 6,920 × 108
case participant_id probe_count qnr_start qnr_finished
<dbl> <chr> <dbl> <dttm> <dttm>
1 2505 Q3ZDH21YQE 84 2023-02-23 17:34:33 2023-02-23 17:36:32
2 2507 Q3ZDH21YQE 84 2023-02-24 09:11:40 2023-02-24 09:13:47
3 2511 Q3ZDH21YQE 84 2023-02-24 12:31:35 2023-02-24 12:33:10
4 2513 Q3ZDH21YQE 84 2023-02-24 13:21:36 2023-02-24 13:22:50
5 2523 Q3ZDH21YQE 84 2023-02-24 20:33:11 2023-02-24 20:34:14
# ℹ 6,915 more rows
# ℹ 103 more variables: qnr_time_diff <chr>, date <date>, wday <dbl>,
# finished <dbl>, survey_ticker <dbl>, session <dbl>, session_start <dttm>,
# session_end <dttm>, session_ticker <dbl>, session_bug <dbl>, mood_01 <dbl>,
# mood_04 <dbl>, mood_02 <dbl>, mood_03 <dbl>, mood_05 <dbl>, mood_06 <dbl>,
# context_no_spotify <dbl>, gneedsat_01 <dbl>, gneedsat_02 <dbl>,
# gneedsat_03 <dbl>, gneedsat_04 <dbl>, gneedsat_05 <dbl>, …Da der Datensatz im sog. Langformat ist, gibt es mehrere Zeilen pro Person (eine pro ESM-Fragebogen). Wir zählen mit n_distinct() die Anzahl an individuellen Teilnehmenden:
n_distinct(d_spotify$participant_id)[1] 144Zudem schauen wir uns die Deskriptivstatistiken der relevanten Variablen an. Für die Übung wählen wir die folgenden Variablen aus: stateenter_01 (“Es hat mir Spaß gemacht, diese Musik zu hören.”, 1 = “stimme überhaupt nicht zu” - 5 “stimme voll und ganz zu”), danceability_mean (“Tanzbarkeit”, eine Musikmetadaten-Variable der Spotify API, 0 = “überhaupt nicht tanzbar” bis 100 = “extrem tanzbar”), popularity_mean (ebenfalls eine Musikmetadaten-Variable der Spotify API, 0 = überhaupt nicht beliebt - 100 = extrem beliebt), sowie das Alter der Teilnehmenden age.
d_spotify |>
select(stateenter_01, danceability_mean, popularity_mean, age) |>
report::report_table()Variable | n_Obs | Mean | SD | Median | MAD | Min | Max
------------------------------------------------------------------------
stateenter_01 | 6920 | 4.26 | 0.86 | | 1.48 | 1.00 | 5.00
danceability_mean | 6920 | 0.62 | 0.11 | | 0.10 | 0.00 | 0.94
popularity_mean | 6920 | 0.59 | 0.15 | | 0.14 | 0.01 | 0.95
age | 6920 | 21.70 | 2.52 | 21 | 1.48 | 18.00 | 34.00
Variable | Skewness | Kurtosis | percentage_Missing
------------------------------------------------------------
stateenter_01 | -1.19 | 1.20 | 59.77
danceability_mean | -0.89 | 1.86 | 59.97
popularity_mean | -0.67 | 0.39 | 61.66
age | 1.76 | 5.02 | 0.00Im folgenden Beispiel wollen wir den Zusammenhang zwischen der durchschnittlichen danceability einer Musikhörsession und wahrgenommenen Spaß beim Hören untersuchen.
7.2 Naives OLS Modell (pooling)
Zur Illustration schätzen wir zunächst das naive Regressionsmodell. Dieses Modell ignoriert die Schachtelung bzw. Nicht-Unabhängigkeit der Daten und tut so, als hätten wir T = 6920 unabhängige Fälle.
results_ols <- lm(stateenter_01 ~ danceability_mean, data = d_spotify)
report::report_table(results_ols)Parameter | Coefficient | 95% CI | t(2766) | p | Std. Coef.
------------------------------------------------------------------------------
(Intercept) | 3.72 | [3.55, 3.90] | 41.10 | < .001 | 2.29e-15
danceability mean | 0.87 | [0.59, 1.15] | 6.09 | < .001 | 0.11
| | | | |
AIC | | | | |
AICc | | | | |
BIC | | | | |
R2 | | | | |
R2 (adj.) | | | | |
Sigma | | | | |
Parameter | Std. Coef. 95% CI | Fit
-----------------------------------------------
(Intercept) | [-0.04, 0.04] |
danceability mean | [ 0.08, 0.15] |
| |
AIC | | 6990.12
AICc | | 6990.12
BIC | | 7007.89
R2 | | 0.01
R2 (adj.) | | 0.01
Sigma | | 0.85Der Effekt der danceability ist positiv und statistisch signifikant, aber wir wissen, dass dieser Schätzer und der Standardfehler verzerrt sind. Um die Schachtelung dieser Daten zu inspizieren und zu berücksichtigen, schauen wir uns ein typisches Analyseverfahren mithilfe von Multilevel-Modellierung an, das für ESM und Tracking-Daten häufig verwendet wird.
7.3 Mehrbenenanalyse mithilfe des REWB-Modells
Bei einem Multilevel-Modell mit Längsschnittsdaten (z.B. ESM, Tracking) liegen Messungen/Situationen auf Level 1 sind und Befragte auf Level 2. Die Annahme dabei ist, dass die Unterschiede im mittleren Spaßerleben der Befragten einer Normalverteilung folgen, d.h. manche Befragten haben im Mittel mehr(weniger) Spaß beim Musikhören als andere. Diese Modell wird als Random Effect Within-Between Modell (REWB) bezeichnet, wobei random hier nicht bedeutet, dass die Intercepts pro Person rein zufällig streuen, sondern sie einer Zufallsvariable (Normalverteilung) entsprechen, daher bezeichnen wir Random Effects auch lieber als Varying Effect.
In R kann man Multilevel-Modelle mit dem lme4-Paket schätzen. Die Random (oder besser: nach Personen variierenden) Intercepts werden mit (1 | participant_id) spezifiziert.
7.3.1 ICC
Im ersten Schritt jeder Modellschätzung berechnen wir ein Nullmodel. Das Nullmodel gibt Auskunft darüber, wie sich die Varianz auf die verschiedenen Ebenen verteilt. Diese Varianzen können wir nutzen, um den Intraklassenkorrelationskoeffizient (ICC) zu berechnen, der einen Hinweis darauf gibt, ob ein Multilevel-Modell überhaupt nötig ist.
m0_fun <- lmer(stateenter_01 ~ 1 + (1 | participant_id), data = d_spotify)
report_table(m0_fun)Parameter | Coefficient | 95% CI | t(2781) | p | Effects
--------------------------------------------------------------------------
(Intercept) | 4.27 | [4.20, 4.35] | 109.55 | < .001 | fixed
| 0.41 | | | | random
| 0.76 | | | | random
| | | | |
AIC | | | | |
AICc | | | | |
BIC | | | | |
R2 (conditional) | | | | |
R2 (marginal) | | | | |
Sigma | | | | |
Parameter | Group | Std. Coef. | Std. Coef. 95% CI | Fit
----------------------------------------------------------------------------
(Intercept) | | 0.01 | [-0.08, 0.10] |
| participant_id | | |
| Residual | | |
| | | |
AIC | | | | 6618.23
AICc | | | | 6618.24
BIC | | | | 6636.02
R2 (conditional) | | | | 0.23
R2 (marginal) | | | | 0.00
Sigma | | | | 0.76Sofern wir den ICC manuell berechnen möchten, lassen sich die Informationen aus der Spalte coefficient entnehmen. Darin enthalten sind die Werte für die Varianz auf beiden Ebenen in Form der Standardabweichungen (= Quadratwurzel der Varianz). Die benötigten Werte werden hier als participant_id (Level 2) und Residual (Level 1) bezeichnet.
0.41^2 / (0.41^2 + 0.76^2)[1] 0.2254258Etwa 23% der Varianz werden nach manueller Berechnung durch die Gruppen erklärt, weshalb es in unserem Fall sinnvoll ist, auf ein Multilevel-Modell zurückzugreifen. Wenn der ICC klein ist bzw. bei ESM als Daumenregel um die .3, sollten wir die Schachtelung der Daten berücksichtigen. Das Paket performance besitzt auch eine dedizierte Funktion icc(), welche ebenfalls den Intraklassenkorrelationskoeffizient berechnet. In der Regel nutzen wir diese Funktion und betrachten den Adjusted ICC.
performance::icc(m0_fun)# Intraclass Correlation Coefficient
Adjusted ICC: 0.230
Unadjusted ICC: 0.230Interpretation: Etwa 23% der Varianz im Erleben von Spaß bei der Musiknutzung lässt sich ausschließlich durch Unterschiede zwischen den Teilnehmenden erklären, während die restliche Varianz vermutlich überwiegend von der Nutzungssituation erklärt wird. Ein Multilevel-Modell ist daher notwendig und angemessen.
7.3.2 Within-Between Zerlegung und Zentrierung der Prädiktoren
Praktisch wird jede Prädiktorvariable (nicht die abhängige Variable!) in einen Within-Person (im ESM: situativen Anteil) und einen Between-Person-Bestandteil (im ESM: personenspezifischen Anteil) zerlegt, damit sie einen Nullpunkt hat und interpretierbar ist.
Die Within-Variable repräsentiert die Abweichung der (situativen) danceability vom Personenmittelwert (auch “person mean” genannt), der durchschnittlich gehörten danceability pro Person. Durch die Zentrierung wird von allen individuellen Werten der Prädiktoren der Personenmittelwert abgezogen, d.h. der neue Prädiktor ist als Abweichung vom Personenmittelwert zu verstehen. Der Regressionskoeffizient dieser Variable ist der Within-Effekt.
Dieser within-effekt bedeutet: Wenn eine Befragte im Mittel über alle Situationen Musik auf Spotify mit einer danceability von 3 hört, aber an einem Samstagabend kurz vor einer Party sogar 5, dann bekäme sie in diesem Fall den Wert (+) 2. Wenn sie an einem Sonntagmorgen nach einer Partynacht Songs mit deutlich geringerer danceability, z.B. 1, hört, bekäme sie den Wert -2. Dies führt dazu, dass wir den Koeffizienten dieser Within-Variable dahingehend interpretieren können, dass das Spaßerleben derselben Person um B Einheiten sinkt oder steigt, wenn sie in einer Situation eine Einheit mehr tanzbare Musik gehört hat als sie es normalerweise tut.
Die Between-Variable ist nichts anderes als die Abweichung des Personenmittelwerts vom Gesamtmittelwert der Personenstichprobe (auch “grand mean” genannt). Also die Abweichung des Ausmaßes an tanzbarer Musik, die eine Person über alle Situationen hört, gegenüber dem Stichprobenmittelwert von danceability über alle Personen hinweg. Diesen interpretieren wir folgendermaßen: Das mittlere Spaßerleben einer Person sinkt oder steigt um B Einheiten im Vergleich zu anderen, wenn sie eine Einheit mehr tanzbare Musik gehört hat als andere.
Für die Zentrierung nutzen wir die Kombination aus group_by() + mutate(), um den Within-Prädiktor und den Between-Prädiktor zu berechnen. Das tun wir hier für unseren Prädiktor danceability_mean und für eine weitere Musikeigenschaftsvariable von Spotify, popularity_mean.
d_spotify <- d_spotify |>
# Nach Person gruppieren
group_by(participant_id) |>
mutate(
# Personenspezifischen Mittelwert berechnen
danceability_person_mean = mean(danceability_mean, na.rm = TRUE),
popularity_person_mean = mean(popularity_mean, na.rm = TRUE),
# Wert der einzelnen Beobachtung vom personenspezifischen Mittelwert abziehen
danceability_within = danceability_mean - danceability_person_mean,
popularity_within = popularity_mean - popularity_person_mean,
) |>
# Gruppierung auflösen
ungroup() |>
mutate(
# Personenspezifischen Mittelwert vom Gesamtmittelwert abziehen
danceability_between = danceability_person_mean - mean(danceability_mean, na.rm = TRUE),
popularity_between = popularity_person_mean - mean(popularity_mean, na.rm = TRUE)
)7.3.3 REWB-Modell mit Prädiktoren
Anschließend schätzen wir das erste REWB-Modell für das Spaßerleben, bei dem für danceability nun zwei Prädiktorvariablen im Modell sind - einmal within einmal between.
m1_fun <- lme4::lmer(stateenter_01 ~ danceability_mean_within + danceability_mean_between + (1 | participant_id), data = d_spotify)
report::report_table(m1_fun)Parameter | Coefficient | 95% CI | t(2763) | p
--------------------------------------------------------------------------
(Intercept) | 4.05 | [ 3.38, 4.71] | 11.97 | < .001
danceability mean within | 0.37 | [-0.69, 1.42] | 0.68 | 0.496
danceability mean between | 1.23 | [ 0.92, 1.55] | 7.70 | < .001
| 0.42 | | |
| 0.74 | | |
| | | |
AIC | | | |
AICc | | | |
BIC | | | |
R2 (conditional) | | | |
R2 (marginal) | | | |
Sigma | | | |
Parameter | Effects | Group | Std. Coef.
-----------------------------------------------------------------
(Intercept) | fixed | | 0.01
danceability mean within | fixed | | 0.03
danceability mean between | fixed | | 0.13
| random | participant_id |
| random | Residual |
| | |
AIC | | |
AICc | | |
BIC | | |
R2 (conditional) | | |
R2 (marginal) | | |
Sigma | | |
Parameter | Std. Coef. 95% CI | Fit
-------------------------------------------------------
(Intercept) | [-0.08, 0.10] |
danceability mean within | [-0.06, 0.12] |
danceability mean between | [ 0.09, 0.16] |
| |
| |
| |
AIC | | 6494.49
AICc | | 6494.51
BIC | | 6524.12
R2 (conditional) | | 0.25
R2 (marginal) | | 0.02
Sigma | | 0.74Wie können wir nun die beiden Koeffizienten interpretieren: Der (minimale und nicht-signifikante) Within-Effekt zeigt, dass intra-individuelle Schwankungen in der danceability einer Hörepisode nicht mit Schwankungen im Spaßerleben einhergehen. Mehr oder weniger Tanzbarkeit als sonst macht den Befragten offenbar weder mehr noch weniger Spaß als sonst. Wir sehen aber am positiven Between-Effekt, dass es Unterschiede im mittleren Spaßerleben zwischen dance-affinen und weniger dance-affinen Personen gibt: Personen, die im Mittel mehr tanzbare Musikhören als andere, haben im Mittel auch mehr Spaß an der Musik als andere, oder anders formuliert: Personen, die im Mittel mehr Spaß am Musikhören haben, hören im Mittel etwas weniger tanzbare Musik. Diesen Between-Effekt kann man aber nicht kausal interpretieren, sondern nur als Korrelation.
Wir visualisieren hier noch einmal den Between-Effekt. Wir sehen, dass Personen mit der niedrigsten mittleren Tanzbarkeit einen vorhergesagten Spaßwert von 3.52 aufweisen, während Personen mit der höchsten mittleren Tanzbarkeit einen Wert von 4.67 erreichen. Der Unterschied von etwa 1.15 Punkten auf der fünfstufigen Skala ist damit durchaus substanziell.
preds_m1_fun_between <- marginaleffects::avg_predictions(m1_fun, variables = "danceability_mean_between")
preds_m1_fun_between |>
ggplot(aes(x = danceability_mean_between, y = estimate, ymin = conf.low, ymax = conf.high)) +
geom_line() +
geom_ribbon(alpha = .1) +
labs(x = "Difference in average danceability", y = "Predicted fun")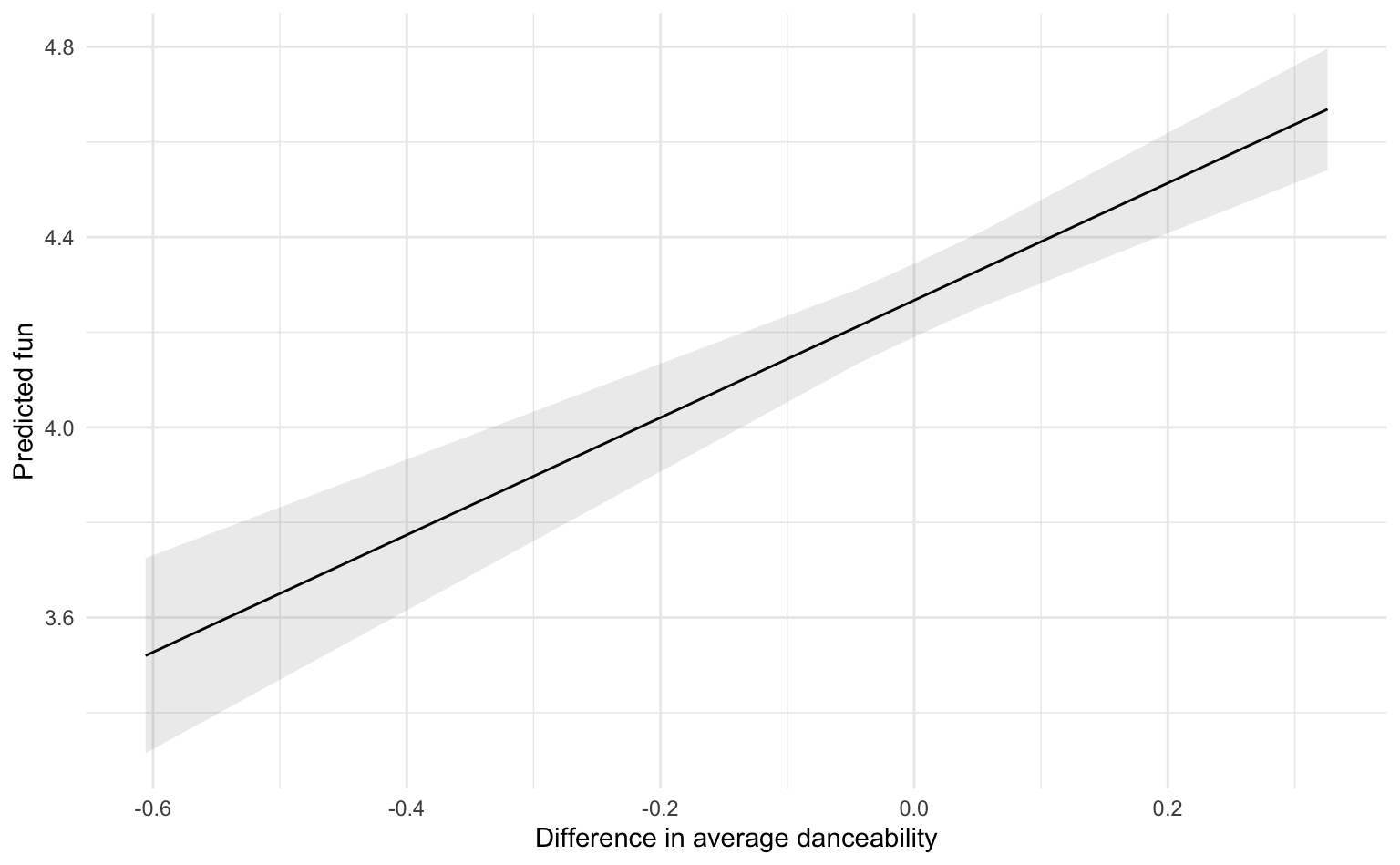
Wollen wir uns neben den Modellvorhersagen zusätzlich noch eine Effektstärke ausgeben lassen, nehmen wir hier meist, das R², das wir auch schon aus Regressionen ohne Mehrebenen-Logik kennen. Wir nutzen das performance-Paket und lesen hier das marginal R2 ab. Das marginale R² beträgt .017, was bedeutet, dass die fixen Effekte (Within- und Between-Effekt der Tanzbarkeit) 1.7% der Gesamtvarianz im Spaßerleben erklären.
performance::r2(m1_fun)# R2 for Mixed Models
Conditional R2: 0.252
Marginal R2: 0.017Sofern theoretisch plausibel, können weitere Kovariaten auf Situations- oder Personenebene ins Modell aufgenommen werden — etwa die Popularität des Songs (Within- und Between-Komponente) oder das Alter der Person. Ein zentraler Vorteil der Within-Between-Zerlegung ist jedoch, dass die Zentrierung der Prädiktoren automatisch für alle stabilen Personeneigenschaften kontrolliert — auch für unbeobachtete. Das bedeutet: Wenn uns primär der Within-Effekt interessiert, also ob situative Schwankungen in der Tanzbarkeit mit Schwankungen im situativen Spaßerleben einhergehen, ist durch die Zentrierung bereits für jegliche stabile Heterogenität zwischen Personen kontrolliert, ohne diese explizit messen oder als Kovariate aufnehmen zu müssen - das macht das REWB-Modell so attraktiv. Die Kontrolle für das Alter der Teilnehmenden hätte es streng genommen also hier nicht gebraucht, wenn uns nur die within-Zusammenhänge interessieren.
m2_fun <- lme4::lmer(stateenter_01 ~
danceability_mean_within + danceability_mean_between +
age +
popularity_mean_within + popularity_mean_between +
(1 | participant_id), data = d_spotify)
report::report_table(m2_fun)Parameter | Coefficient | 95% CI | t(2643) | p
--------------------------------------------------------------------------
(Intercept) | 3.69 | [ 2.45, 4.92] | 5.86 | < .001
danceability mean within | 0.39 | [-0.73, 1.52] | 0.69 | 0.492
danceability mean between | 1.20 | [ 0.88, 1.53] | 7.19 | < .001
age | 8.31e-03 | [-0.02, 0.04] | 0.49 | 0.624
popularity mean within | 0.28 | [-0.53, 1.10] | 0.68 | 0.495
popularity mean between | 0.36 | [ 0.10, 0.62] | 2.71 | 0.007
| 0.42 | | |
| 0.74 | | |
| | | |
AIC | | | |
AICc | | | |
BIC | | | |
R2 (conditional) | | | |
R2 (marginal) | | | |
Sigma | | | |
Parameter | Effects | Group | Std. Coef.
-----------------------------------------------------------------
(Intercept) | fixed | | 0.01
danceability mean within | fixed | | 0.03
danceability mean between | fixed | | 0.12
age | fixed | | 0.02
popularity mean within | fixed | | 0.03
popularity mean between | fixed | | 0.05
| random | participant_id |
| random | Residual |
| | |
AIC | | |
AICc | | |
BIC | | |
R2 (conditional) | | |
R2 (marginal) | | |
Sigma | | |
Parameter | Std. Coef. 95% CI | Fit
-------------------------------------------------------
(Intercept) | [-0.08, 0.10] |
danceability mean within | [-0.06, 0.13] |
danceability mean between | [ 0.09, 0.16] |
age | [-0.07, 0.12] |
popularity mean within | [-0.06, 0.12] |
popularity mean between | [ 0.01, 0.08] |
| |
| |
| |
AIC | | 6221.22
AICc | | 6221.28
BIC | | 6268.29
R2 (conditional) | | 0.26
R2 (marginal) | | 0.02
Sigma | | 0.747.4 Hausaufgabe
Schauen Sie sich die Variablenlabels zu d_spotify an mithilfe von labelled::var_label(d_spotify) an. Untersuchen Sie einen Zusammenhang zwischen einem Prädiktor Ihrer Wahl und einer abhängigen Variable auf Situationsebene mit einem REWB-Modell an. Tipp: Suchen Sie sich eine (quasi-)metrische abhängige Variable auf Situationsebene (Level 1) aus. Fügen Sie in einem zweiten Schritt eine plausible Kovariate hinzu. Berichten und visualieren Sie die Ergebnisse.