library(performance)
library(see)
library(report)
library(tidyverse)
theme_set(theme_minimal())5 Modellannahmen
Beispielanalyse
Welche Variablen sagen politisches Wissen voraus?
5.1 Pakete und Daten laden
Wir laden die üblichen Paket sowie das performance-Paket, dass viele Funktionen zur Prüfung von Modellannahmen und Modellgüte enthält. Dieses erfordert zusätzlich see für die Visualisierung der Checks. Wir verwenden denselben Datensatz wie in der letzten Übung.
vanerkel21 <- haven::read_sav("data/Vanerkel_Vanaelst_2021.sav") |>
mutate(
Education = as_factor(Education),
Gender = as_factor(Gender)
) |>
haven::zap_labels()
vanerkel21# A tibble: 993 × 74
StartDate_w3 EndDate_w3 Duration__in_seconds_w3 Gender Year_of_birtg Age
<date> <date> <dbl> <fct> <dbl> <dbl>
1 2019-04-09 2019-04-09 440 female 29 45
2 2019-04-09 2019-04-09 504 female 43 59
3 2019-04-06 2019-04-06 610 female 36 52
4 2019-04-03 2019-04-03 414 female 7 23
5 2019-04-09 2019-04-09 1274 female 7 23
# ℹ 988 more rows
# ℹ 68 more variables: Education <fct>, News_channels_w3_1 <dbl>,
# News_channels_w3_2 <dbl>, News_channels_w3_3 <dbl>,
# News_channels_w3_4 <dbl>, News_channels_w3_5 <dbl>,
# News_channels_w3_6 <dbl>, Political_interest <dbl>, StartDate_w4 <date>,
# EndDate_w4 <date>, Duration__in_seconds__w4 <dbl>,
# News_channels_w4_1 <dbl>, TV <dbl>, Newspaper <dbl>, Websites <dbl>, …5.2 Regressionsmodell
Ausgangspunkt ist eine multiple Regression, in der wieder politisches Wissen durch soziodemographische Prädiktoren sowie politisches Interesse erklärt wird.
m1 <- lm(PK ~ Gender + Age + Education + Political_interest, data = vanerkel21)
report::report_table(m1)Parameter | Coefficient | 95% CI | t(987) | p | Std. Coef. | Std. Coef. 95% CI | Fit
--------------------------------------------------------------------------------------------------------------
(Intercept) | 0.46 | [ 0.09, 0.83] | 2.45 | 0.014 | -0.13 | [-0.27, 0.02] |
Gender [female] | -0.51 | [-0.65, -0.37] | -6.96 | < .001 | -0.37 | [-0.48, -0.27] |
Age | 0.02 | [ 0.02, 0.03] | 8.48 | < .001 | 0.23 | [ 0.17, 0.28] |
Education [Middle] | 0.35 | [ 0.13, 0.56] | 3.15 | 0.002 | 0.26 | [ 0.10, 0.41] |
Education [High] | 0.60 | [ 0.38, 0.82] | 5.42 | < .001 | 0.44 | [ 0.28, 0.60] |
Political interest | 0.20 | [ 0.18, 0.23] | 14.76 | < .001 | 0.40 | [ 0.35, 0.45] |
| | | | | | |
AIC | | | | | | | 3021.38
AICc | | | | | | | 3021.49
BIC | | | | | | | 3055.69
R2 | | | | | | | 0.35
R2 (adj.) | | | | | | | 0.34
Sigma | | | | | | | 1.10Das Modell kann rund ein Drittel der Varianz in politischem Wissen erklären. Politisches Interesse, hohe Bildung und Geschlecht haben den stärksten Zusammenhang mit dem Wissen.
5.3 Annahmen
Für die Prüfung der klassischen OLS-Annahmen wie Linearität, Normalverteilung der Residuen, Homoskedastizität und Multikollinearität gibt es im performance-Paket eine Sammelfunktion, die schlicht check_model() heißt. Die Ergebnisse lassen sich über die plot() Funktion als Reihe von Grafiken samt Erklärungen ausgeben.
checks <- performance::check_model(m1, panel = F)
plot(checks)$PP_CHECK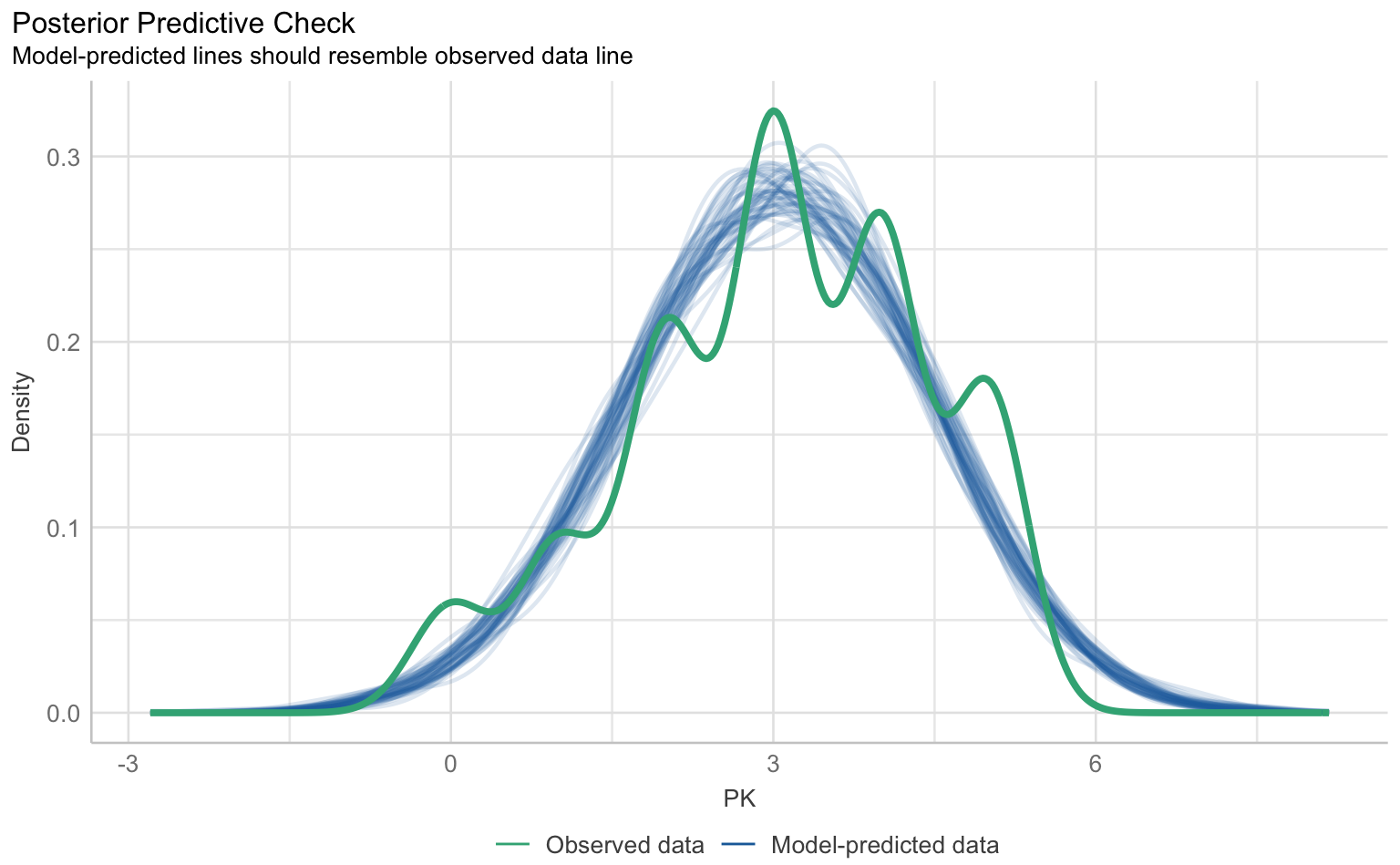
$NCV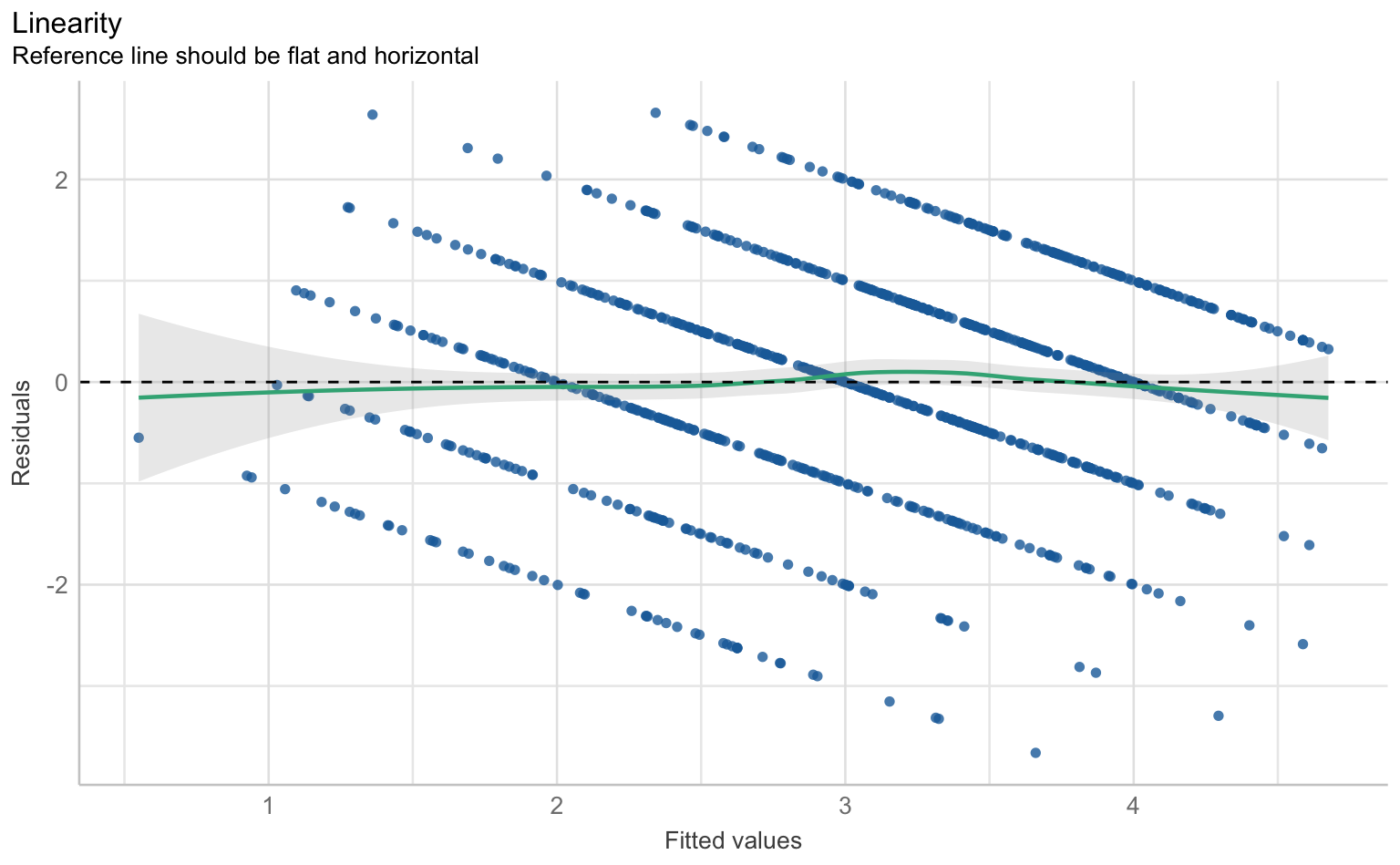
$HOMOGENEITY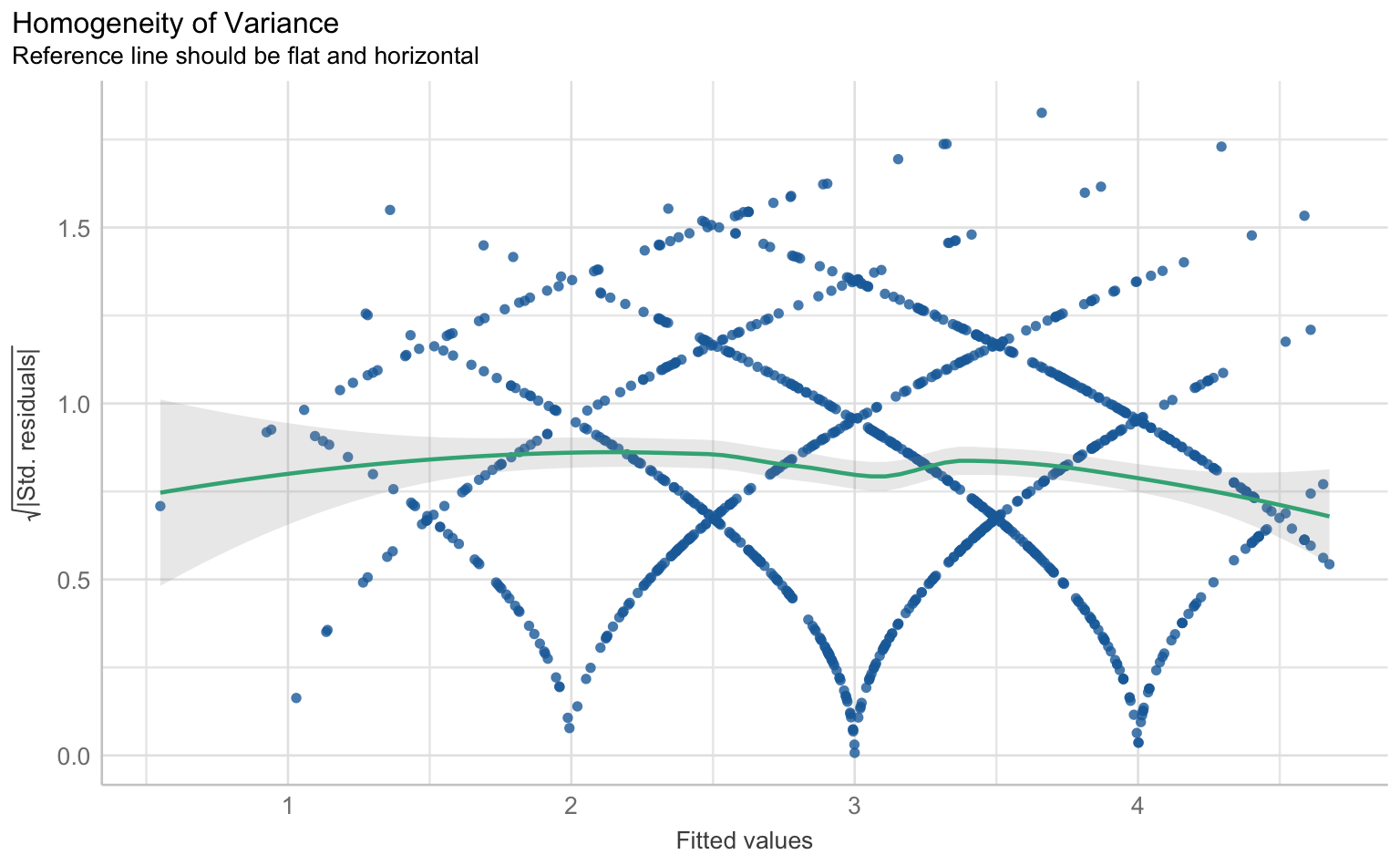
$OUTLIERS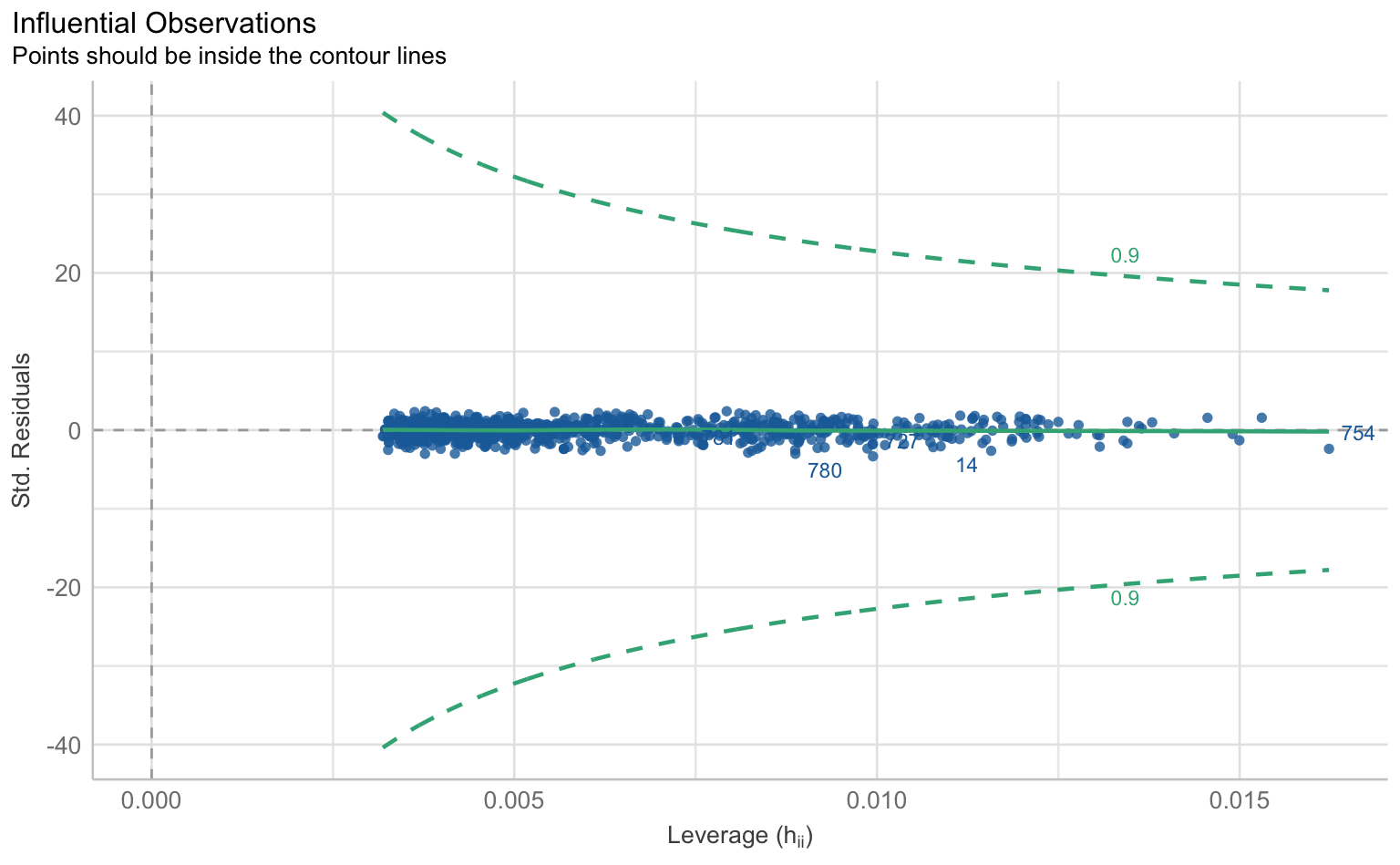
$VIF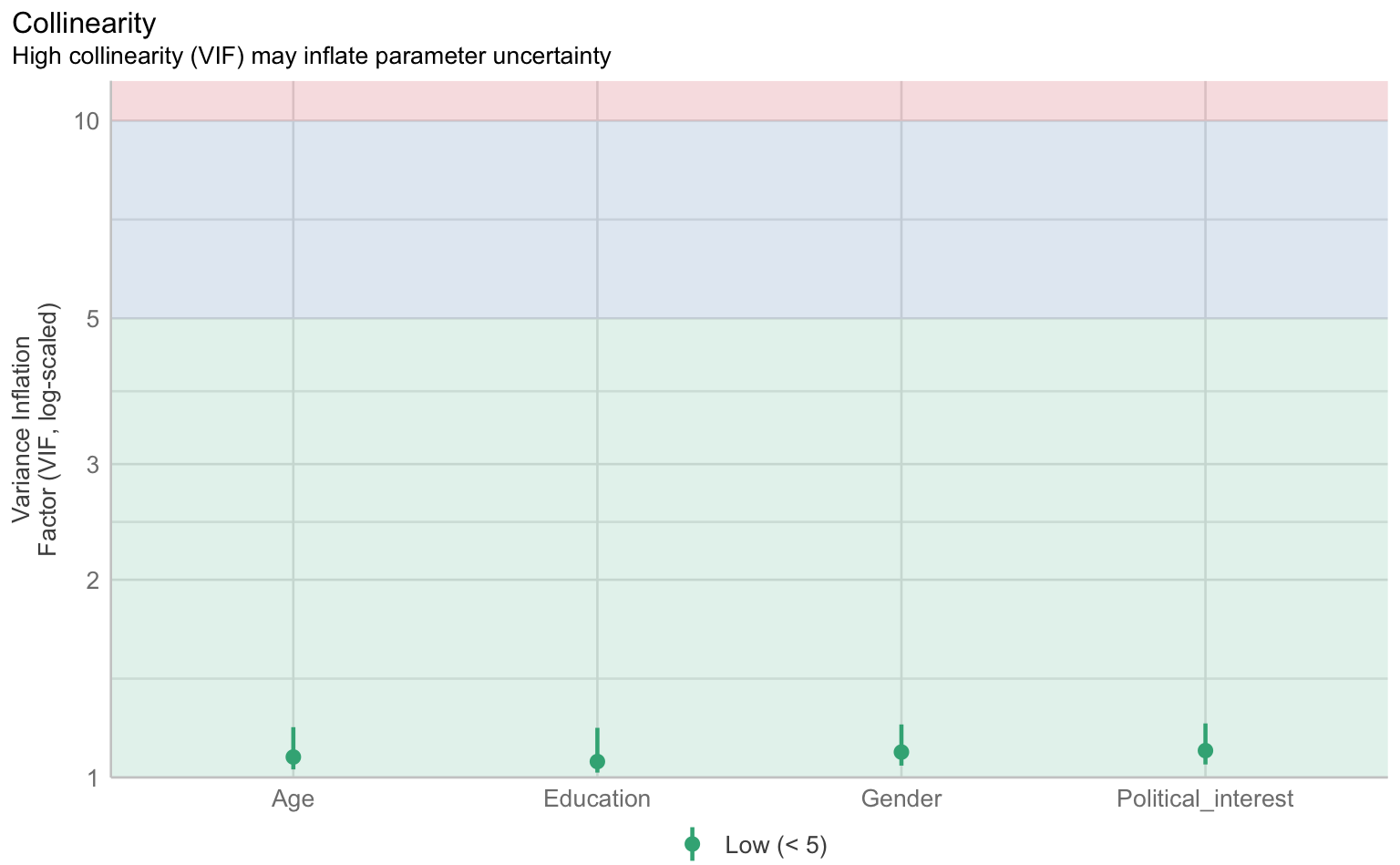
$QQ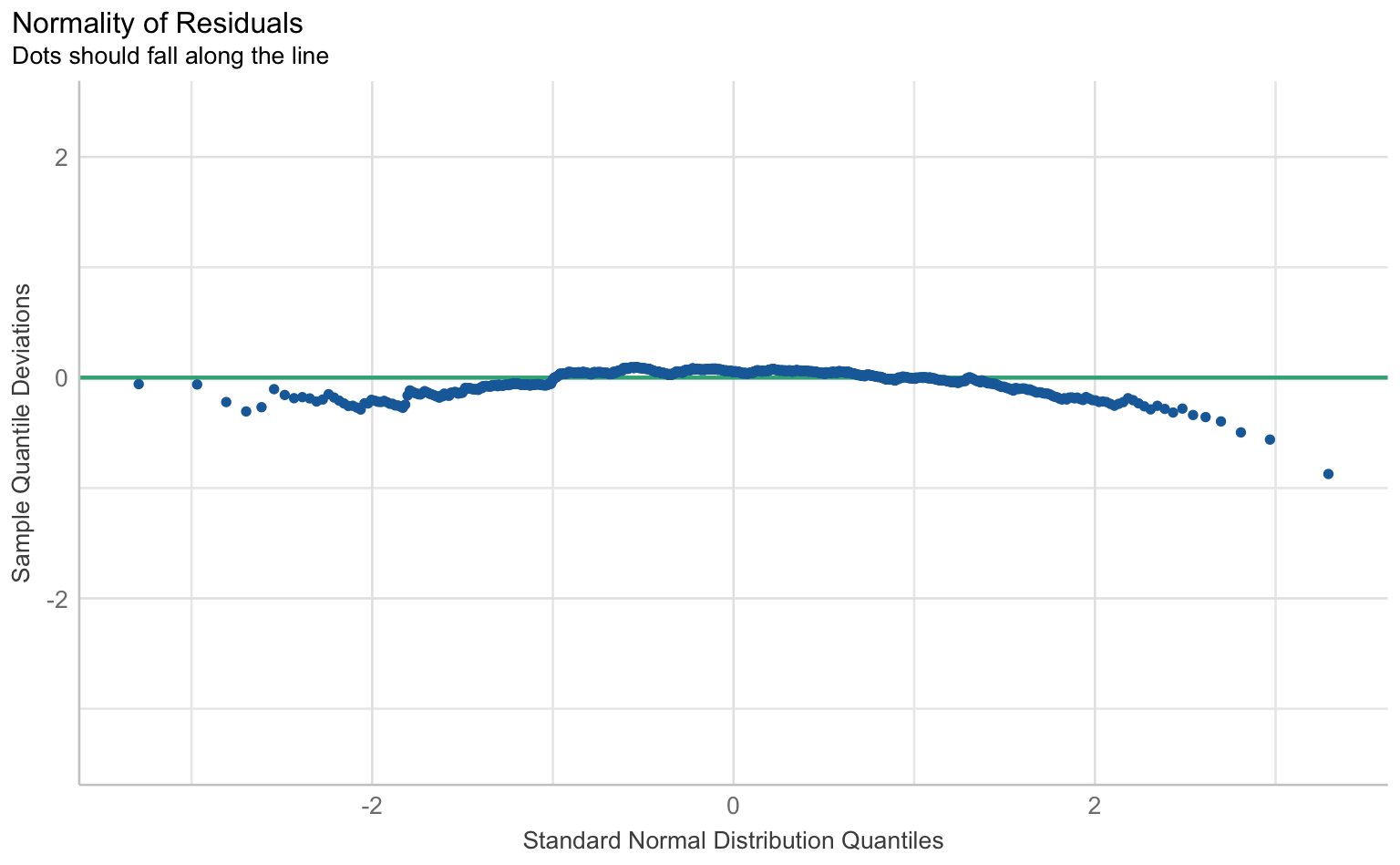
Über die Hilfe-Funktion in R bekommen wir ausführliche Hinweise zur Interpretation der einzelnen Tests und Plots.
?performance::check_model